LLM dataminer system
之前開啓了一個項目,要做游戲内部知識庫,去年用 rag/ragraph 做游戲知識庫發現出來的結果不怎樣,轉頭去做了其他的應用
後來大概分析出幾個問題
- raw data 其實不適合直接進入 vector database
- 不同應用場合需要不同配套措施
- 本地的 ollma 不堪負荷,使用了 cc subproc 效果就好很多,哪怕用 qwen 都比其他好
後來3月份又開始重啓了這個項目,不過最近在搞其他事情,項目只是先把框架跟工程概念梳理了,遠還沒進入數據清洗階段
好消息是之前寫的 yt download mp4 跟 qwen asr 轉字幕派上用途了,套在游戲的現有 op 字幕截取省事多了,原本要將素材對到 字幕時間點是個麻煩的細節工,有了這些幾乎只需要 beyongcompare,一個全新的 op movie 10分鐘就搞定了,雖然最終這個 op 編輯器沒發揮價值....
rag 工具(QWen3-ARS不可用....因爲忘了開 ollama,電腦在跑 comfyUI 整個 gpu loading 卡的很死)
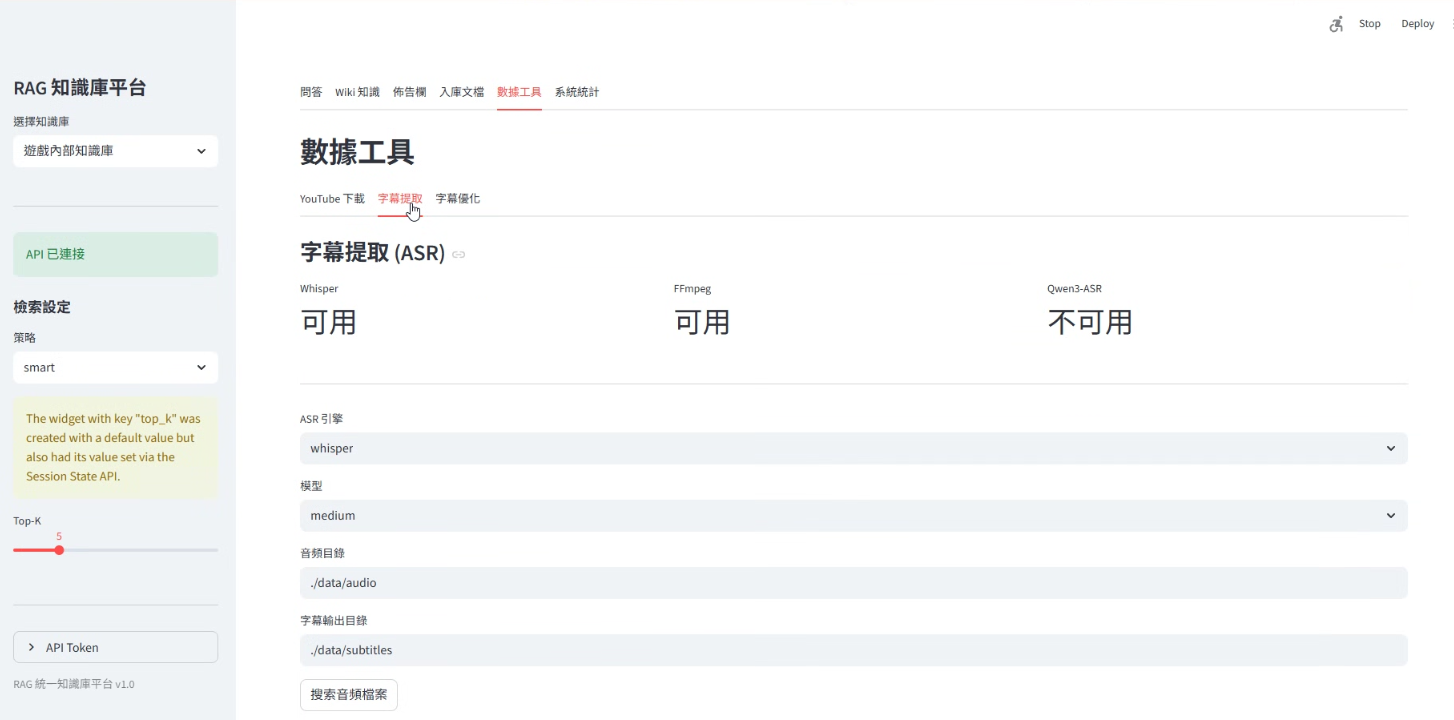
有些東西不方便放上來,感興趣可以問問,但鑒於目前項目進度也就 30~40%,其實沒什麽能看的
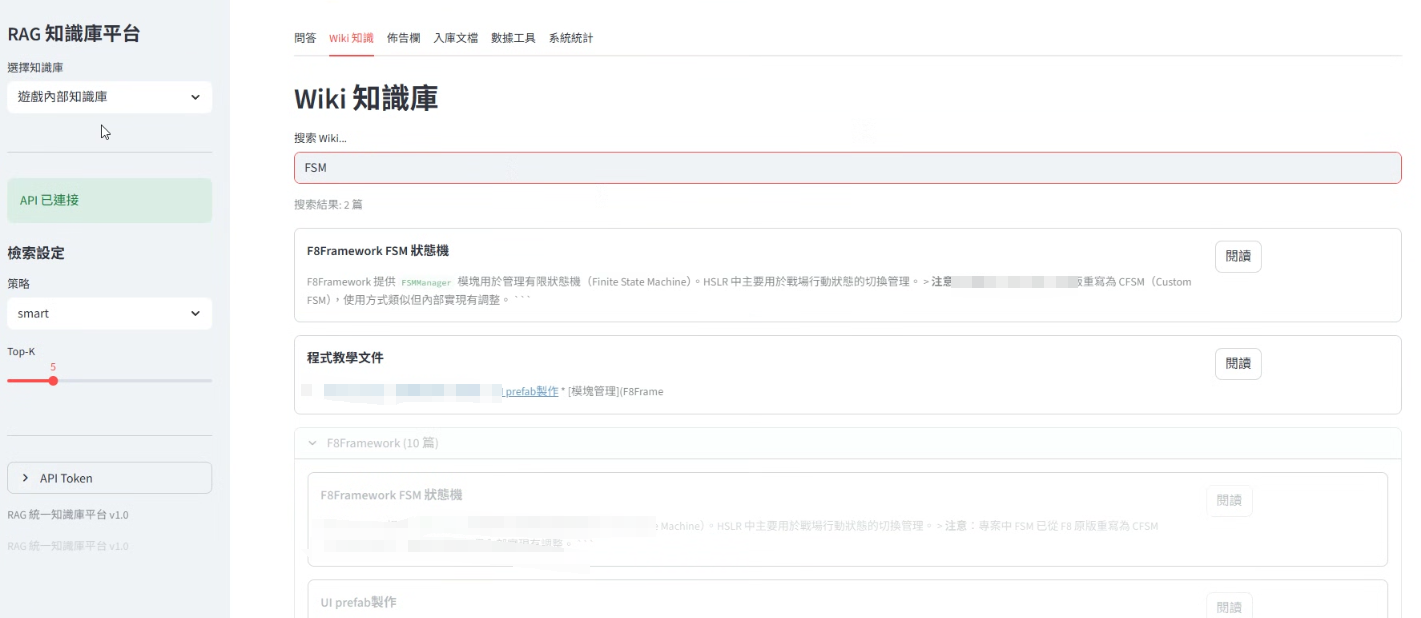
然後前陣子看到 Andrej Karpathy 發佈的 LLM wiki,概念應該很相似,改天有空也來看看,不過整體架構的可行性評估下來在7-8成,問題也不大。
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f