熵的鏈式法則與最大熵原則:多階段決策的資訊熵拆解與最大熵推斷
熵的鏈式法則(Chain Rule)
$H(X)=H(X1)+H(X2∣X1)+H(X3∣X1,X2)$
如果一個決策可以拆成連續幾個階段,總熵 = 每個階段的熵之和(後面的階段用「條件熵」,也就是在前面已知的情況下,那個階段還剩多少不確定性)。
urscos Tech.
$H(X)=H(X1)+H(X2∣X1)+H(X3∣X1,X2)$
如果一個決策可以拆成連續幾個階段,總熵 = 每個階段的熵之和(後面的階段用「條件熵」,也就是在前面已知的情況下,那個階段還剩多少不確定性)。
之前一直以爲游戲在A熒幕啓動是無法獲取熒幕B的解析度清單,特地問了claude,發現跟認知有所差異,特地備注處理方式,下面是claude給的答復。

「以前拿不到」的印象是對的
Screen.resolutions 概念上一直是回傳「視窗當前所在螢幕」的清單,但舊版 Unity(約 2019/2021 以前)有快取/刷新的 bug,跨螢幕後常常只回主螢幕的清單、或根本不更新。多螢幕支援在 Unity 2021~6 大幅改善,現在把視窗拖到 B 就會回 B 的清單。所以你「以前拿不到 → 現在拿得到」的記憶落差,是真實的版本行為變化。
$|\phi_0\rangle$ 讀作「ket phi zero」,中文可以念成「右括號 phi 零」。
它代表一個量子狀態,也可以把它暫時理解成一個向量。
例如普通二維向量可以寫成:
$$
|\phi_0\rangle= \begin{pmatrix} 1\\ 0 \end{pmatrix}, \qquad |\phi_1\rangle= \begin{pmatrix} 0\\ 1 \end{pmatrix}
$$
目前常規的PC游戲顯示模式有幾種模式如下,
FPS游戲多數使用獨占模式,也是最早的全屏幕模式,性能較好,但使用 Alt+Tab時切換會出現閃頻
目前游戲多數使用這個模式,開啓後切換不會出現閃屏
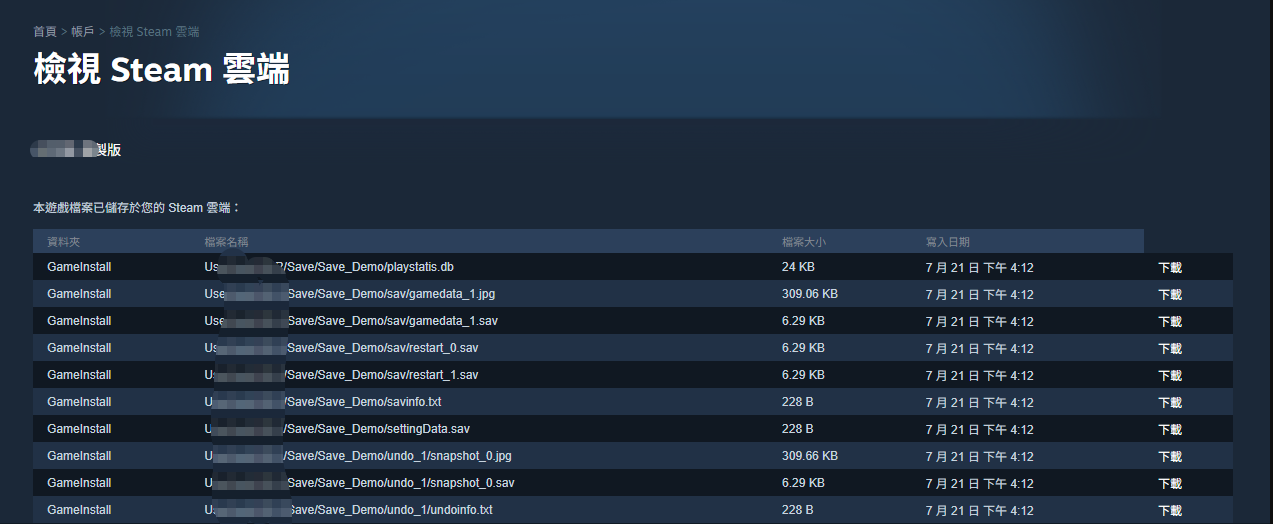
輸入網址 https://store.steampowered.com/account/remotestorage
然後滾動到想查看的游戲,點擊顯示檔案

可以看到目前游戲下的所有雲端存檔
使用 WIN+R 輸入指令開啓 steam 主控臺