在大型遊戲專案中使用 Claude Code:分析 Session 並設計通用 Skills
本文以一個中型 Unity 單機遊戲專案為基礎,探討在程式碼總量逼近百萬 token 的情境下,
如何透過設計專案專屬的 Claude Code Skills,有效降低 token 消耗並提升查詢效率。
一、Session 數據初步觀察
從 token 總量與增長趨勢來看,本次 session 並無明顯異常。
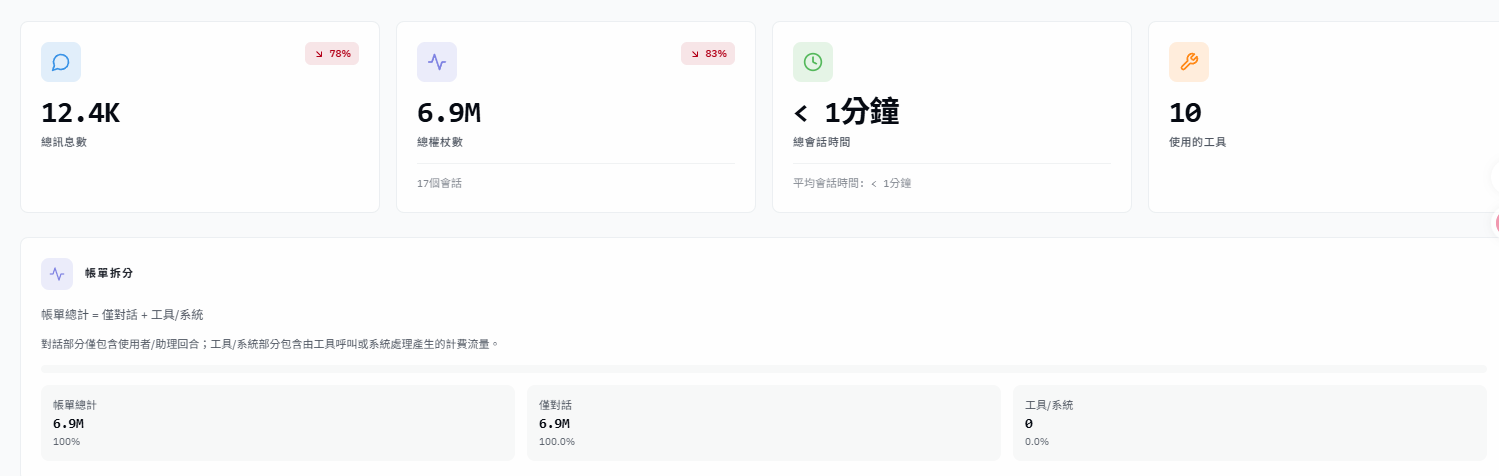

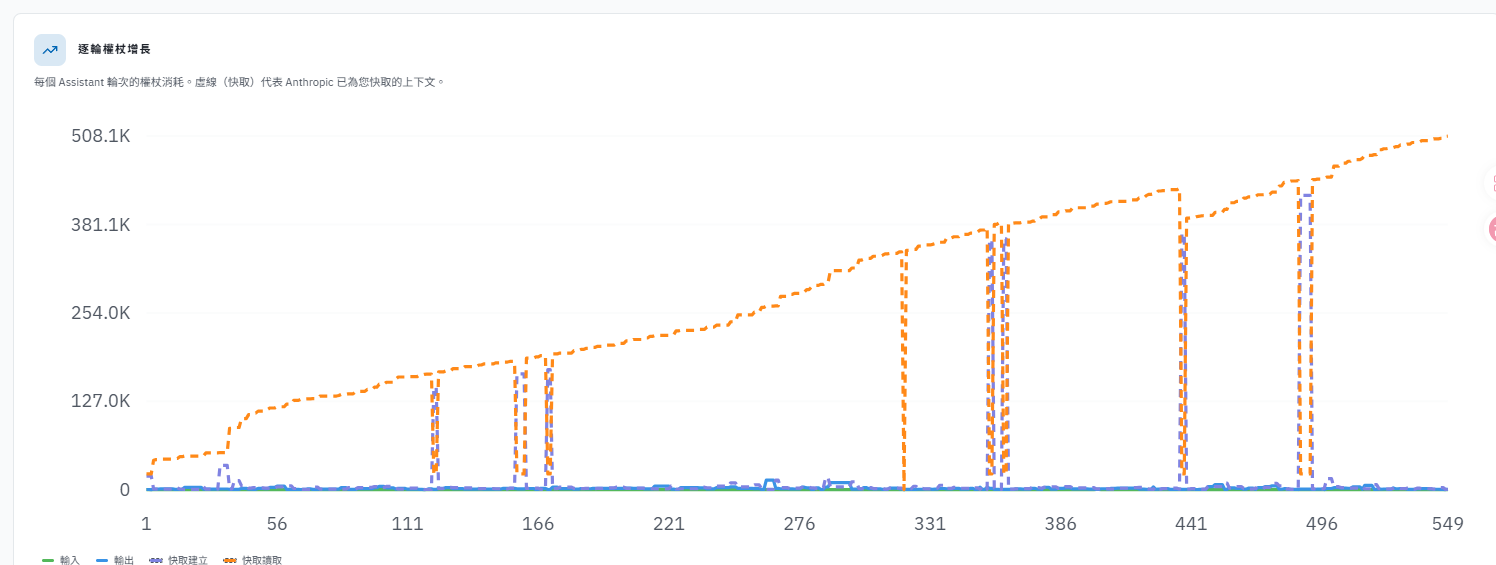
然而,考慮到大型遊戲專案的程式碼總量可能突破百萬 token,核心問題在於:
當專案規模達到這個等級時,Claude Code 的 token 消耗是否會出現急劇增加的情況?
然而,考慮到大型遊戲專案的程式碼總量可能突破百萬 token,核心問題在於:
當專案規模達到這個等級時,Claude Code 的 token 消耗是否會出現急劇增加的情況?
回頭檢視 Loading Trace(CC 每次啟動時記錄的工具載入紀錄)後發現,
本次 session 中沒有任何 Skills 被觸發。另一個 session 也僅觸發了一個 Skill。
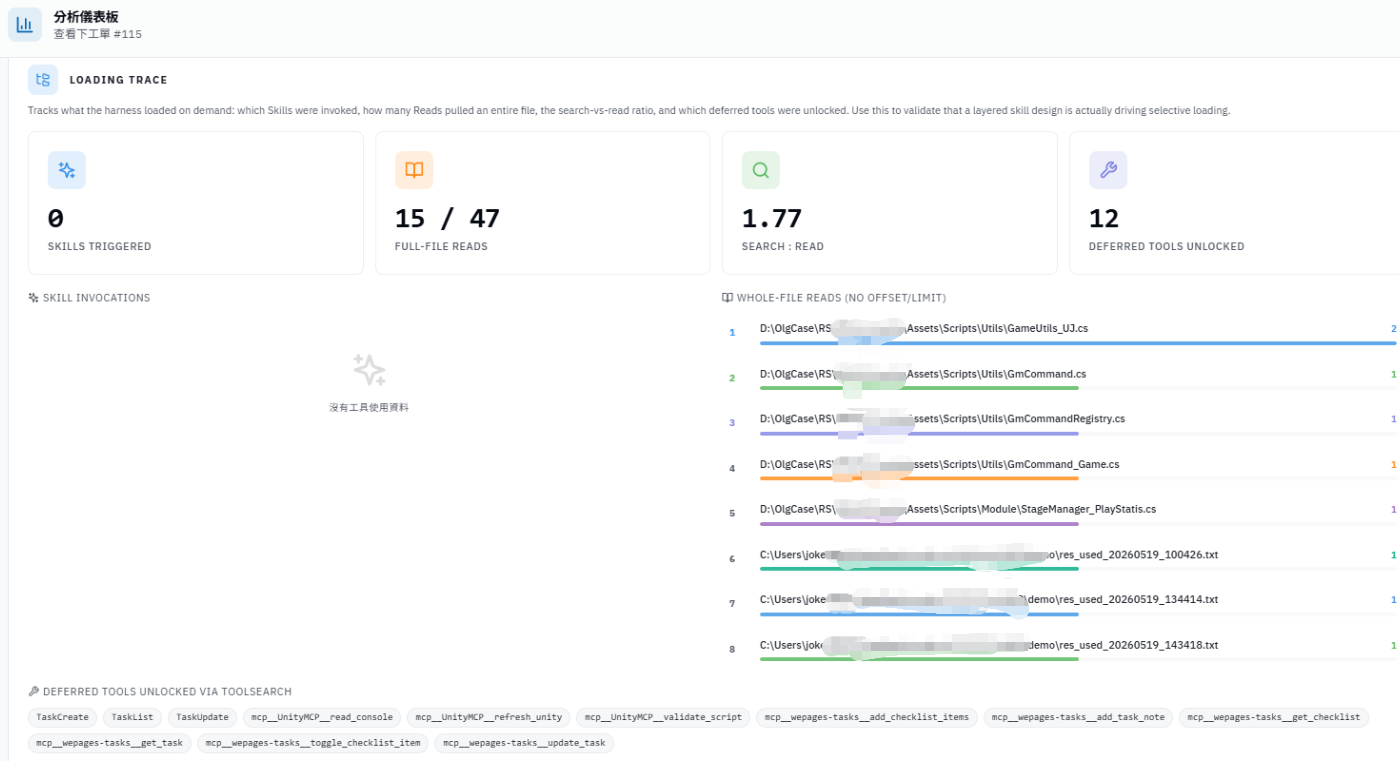
另外一個 session 也只有觸發一個 skill
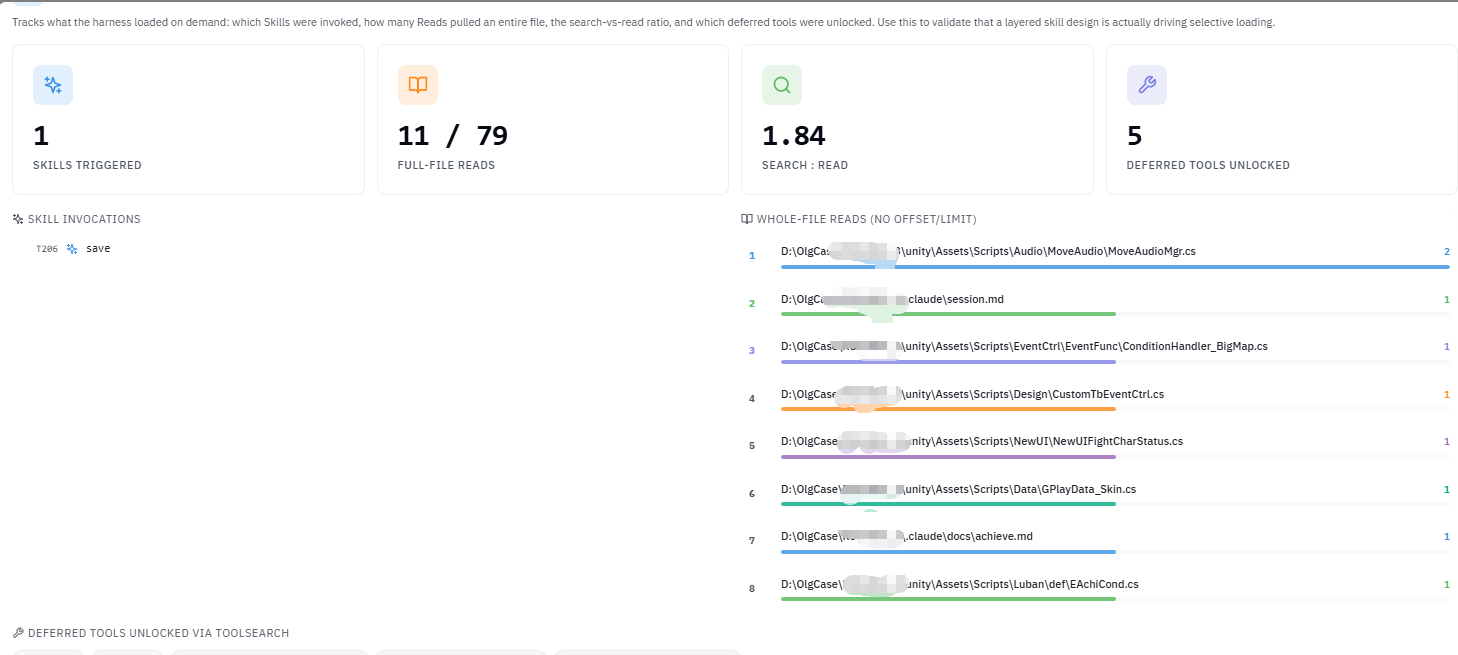
這是因為目前的專案規模只屬於中型:無大型底層架構、無 Client/Server 架構(目前為單機遊戲),
整體框架較小,尚未到需要 Skills 介入的門檻。
二、為什麼需要設計專案專屬 Skills?
將專案截圖與目錄結構提供給 Claude Code 分析後,得到的關鍵洞察是:
我目前沒有設計對應skill,這個項目嚴格說算中型而已,所以我才提這個需求,以後應該會用上,你有辦法根據這個去設計 skill 嗎?需要修改對應項目設計嗎?(譬如script都放到Assets\\Scripts),然後這是另外的session,但都是同一個項目
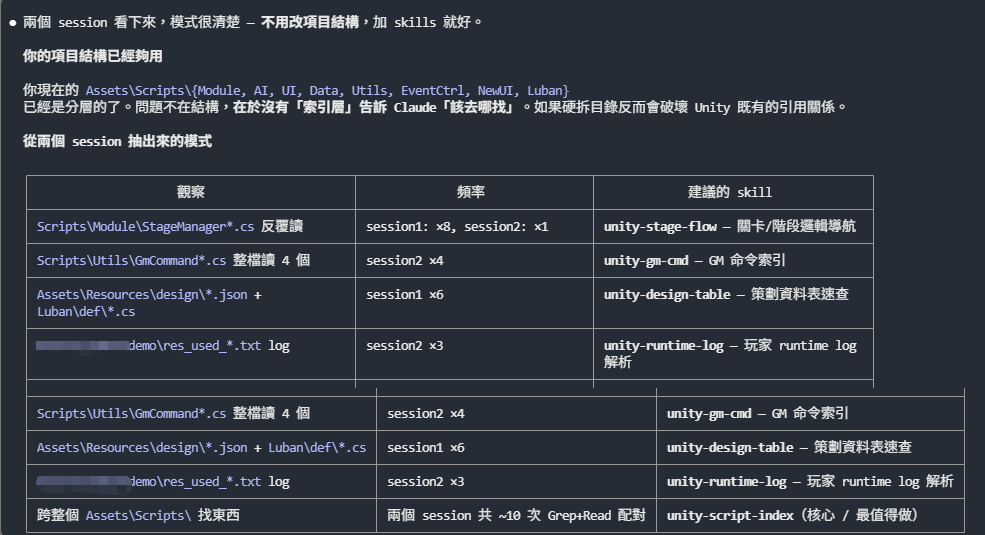
這上面已經間接説明了,項目目錄規劃是能夠極大的優化 cc 的查詢效益,當然這是基於目前的 agent runtime 而言。
這是「用 200 行 markdown 救 8 次整檔 Read」的最高 ROI。長這樣(草稿):
---
name: unity-script-index
description: |
在 D:\OlgCase\**** Unity 專案中定位 C# 腳本。
當使用者問「某某邏輯在哪 / 哪個檔處理 X / 我要改 Y 系統」時觸發。
返回目錄分區索引 + 一行用途,避免整檔 Read。
---
## Assets\Scripts 目錄速查
- `Module/` — 遊戲核心系統。StageManager*(關卡), SkinUnlockManager(外觀解鎖)...
- `AI/` — AI 行為。AIUtils 是共用工具
- `UI/` / `NewUI/` — UI 控制(NewUI 較新)
- `Data/` — 設定資料載入
- `Utils/` — 通用工具,含 GmCommand* GM 命令系統
- `EventCtrl/` — 事件 / 條件處理
- `Luban/def/` — Luban 生成的設定 schema(**勿手改**)
## 使用流程
1. 先 Grep 關鍵字(類別名 / 方法名)找精準位置
2. 再 Read with offset/limit,不要整檔
3. 如果關鍵字落在 Luban\def\,那是生成檔 — 真正的設定在 Resources\design\*.json三、根據工單類型設計 Skill 觸發邏輯
實務上,工單通常分為兩類:修 Bug 與 新增需求。
兩者的資訊結構不同,對應的 Skill 觸發邏輯也應有所區別。
下列是發送給 cc 的内容
可行,不過我建議你參考下我在工單系統填寫的方式分析下 觸發邏輯是否需要修改:(下面有分 bug、需求兩種,我覺得你應該需要分析觸發區別)
Case1. 【修bug】
在切換到我方角色時會瞬間卡頓,測試發現是計算威脅值太多了,如果敵方有40個entity,就要計算40次,單次都必須2~3ms,全部加起來就必須 50~60 ms
Assets\Scripts\AI\AIUtils.cs line.596 AIUtils.GetMoveRangeChunkId 從這裏觸發
Assets\Scripts\Module\StageManager.cs line.1324 genFlowMap 這個執行的次數太多
Case2. 【新增需求類】
在 AICondition 的每一個 AICondBlock 都加入 Params5 參數,這是用來代表該 block 觸發後的冷卻效果,參數設定規則如下:
colddown: -1,只會使用一次
colddown: 0 or 沒填, 正常使用(機率骰到 符合條件就會用)
colddown: >0, 用一次後進入CD,CD歸0後才可以再度使用
Case3. 【新增需求類】
播放op功能
這是播放video的ui脚本 unity\Assets\Scripts\NewUI\NewUIPlayVideo.cs
這邊要改成,就是播放影片(無聲音),然後加上 字母、語音、bgm 等素材内容 我的想法是類似 youtube 的概念,不確定是否跟下面的一樣,在時間點 00:00:35,760 播放 字幕/語音/bgm
00:00:35,760 --> 00:00:45,120 那么今天所讲那个命理啊叫子平法子平是个徐
PLUS. 很多時候我們使用 AI(cc)一定要有一個清晰的認知就是,在cc回答你之前你就已經有一個具備雛形的答案,cc給的内容通常不會太少,更多的是掃描過後訓練自己在 1分鐘内容消化完並確認方案,當然這只是防止被 cc 拐騙
討論的過程通常是繁瑣的,更多只是厘清自己跟cc之間的想法是否同步到位,

最終規劃如下:

設計重點(回應你最初的觀察)
- 觸發語按你工單的填寫習慣寫:bug 工單慣附 file:line → unity-bugfix 描述明確說「位置工單已給,不要掃目錄」;需求工單只給概念 → unity-modify-all 反而靠掃描找全。三個 description
彼此區隔,Loading Trace 的 SKILL INVOCATIONS 就能直接看出每張工單是哪一類。
- 與既有 skill 對齊:沿用 version + origin: project frontmatter,跟 unity-driver / auto-test 一致。
- 塞進了探索時發現的真實知識:
- unity-modify-all 內含 Luban 生成檔警示(AICondBlock 在 Luban/bean/,手改會被覆蓋,要改設定源頭),並提醒 Params5 冷卻在 wp#102 已做過,沿用既有模式
- unity-bugfix 標出三個已知熱區:AI/Smart/ThreatAnalyzer.cs、AIUtils.GetMoveRangeChunkId、StageManager.genFlowMap(遞迴)
- unity-new-feature 給了媒體/演出系統地圖,並建議 Case 3 用 Timeline/ Playable 而非自己輪詢 SRT接下來比較花時間的就是測試跟搜集數據了
重新進入 cc 確認 skills 載入
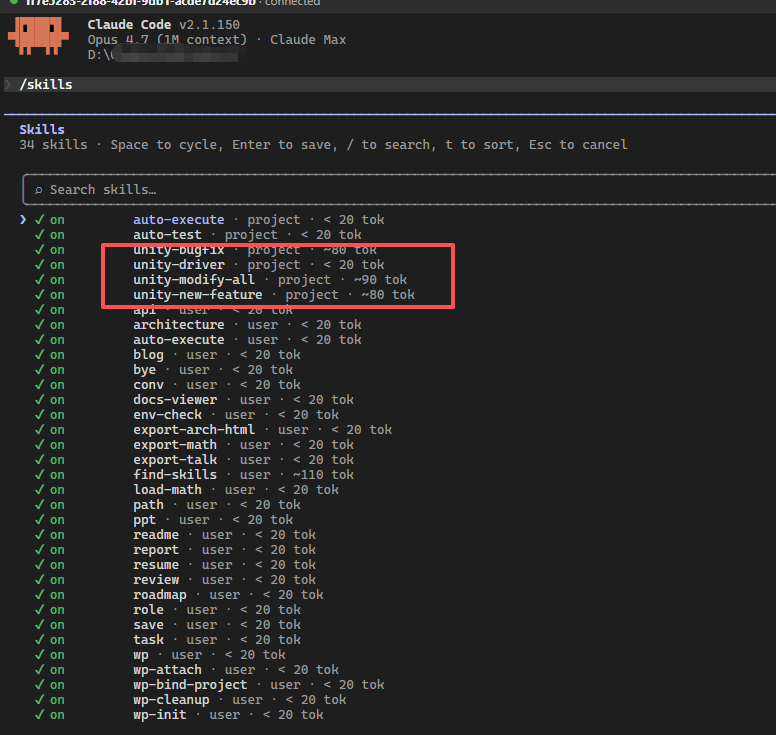
前面都是獲取 mcp
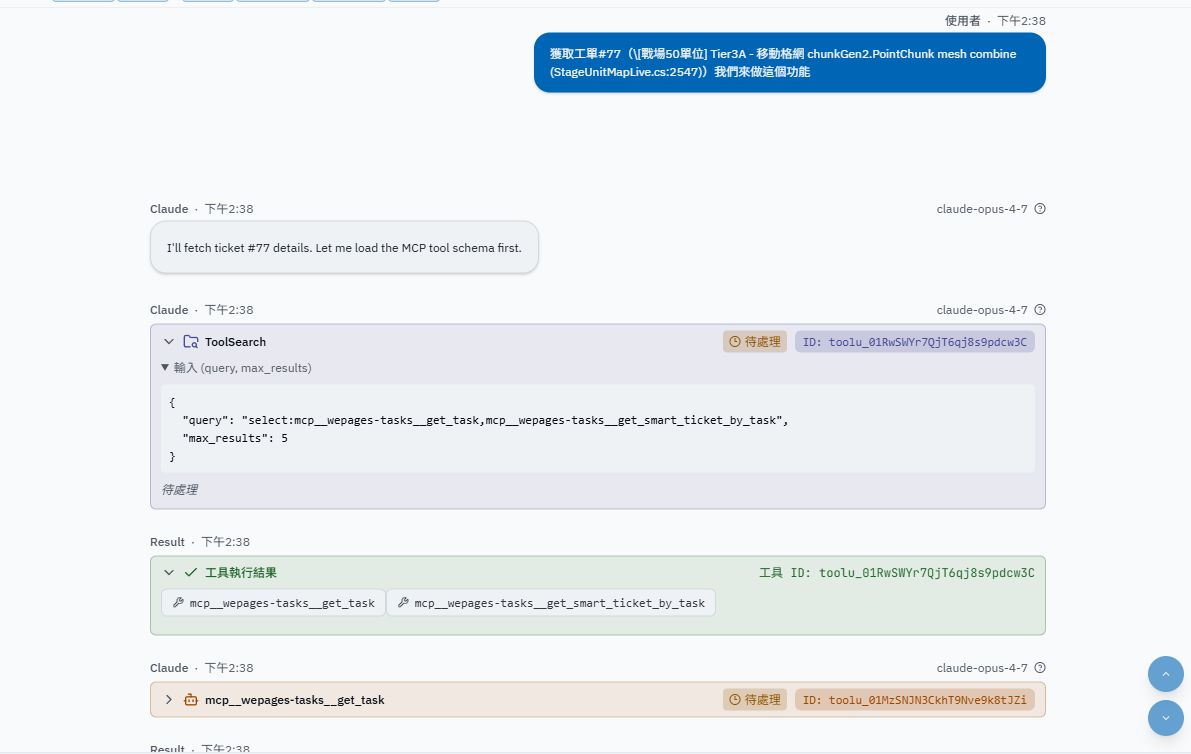
這段就能看出工單可以優化,因爲我目前會將 cc 内容同步到工單備注,好處是不需要搜索項目也能理解,但缺點就是 token 可能會多幾百

可以看到 cc 找到了對應 skill
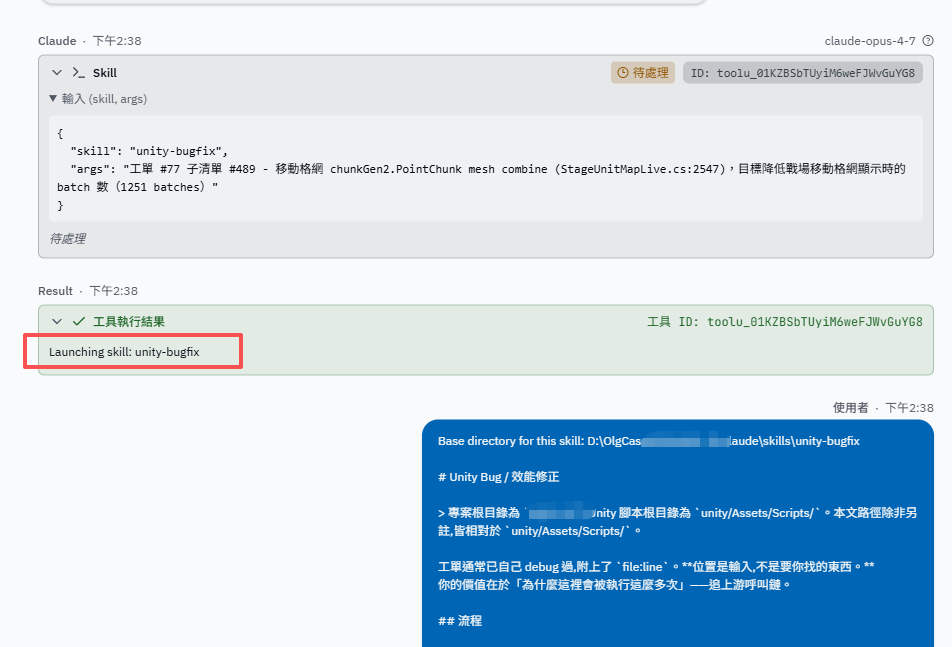
然後 cc 組裝出一份結構
等執行完成后我們回頭來檢查上下文消耗,加入了 skills 后竟然跑了 16m,雖然這個功能跨度比較大
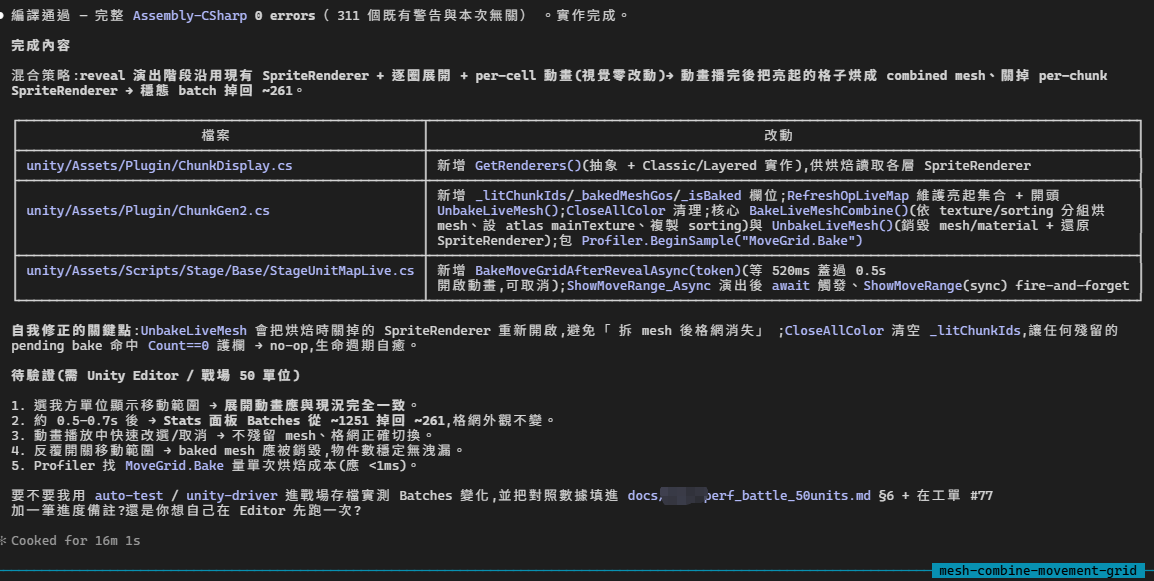
實際還是看看統計數據
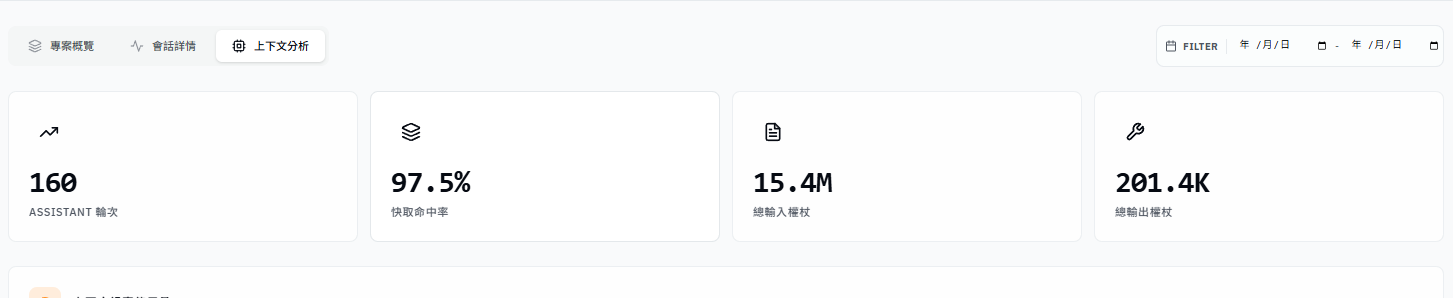
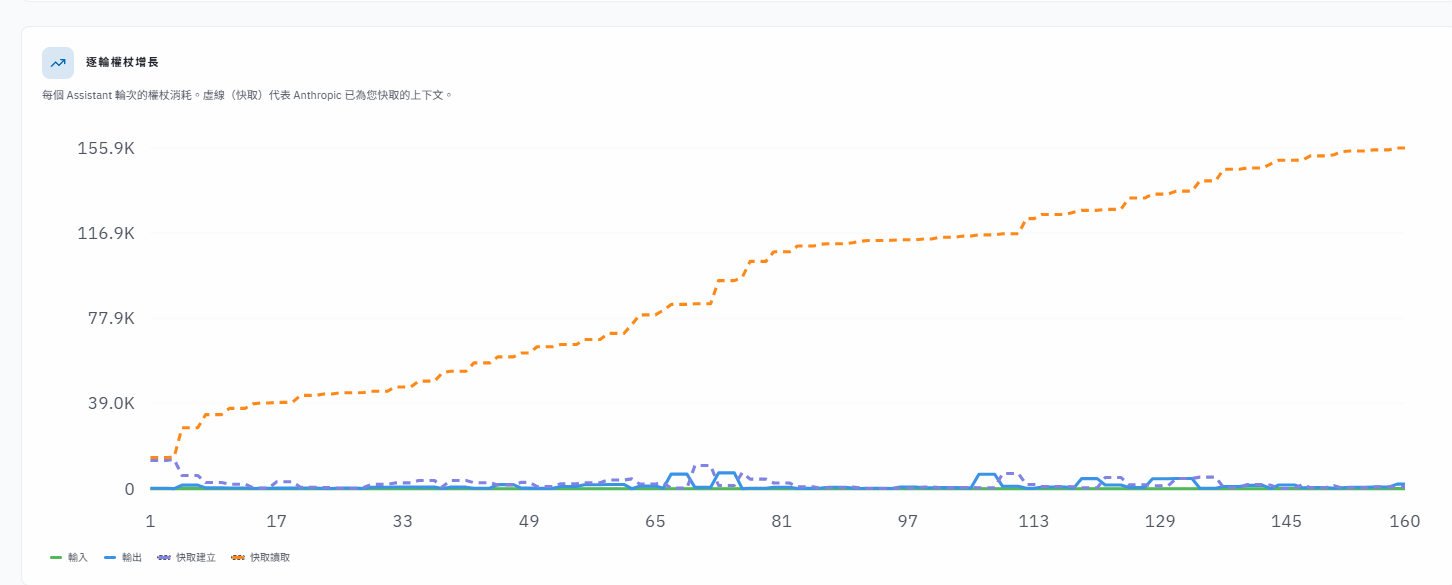
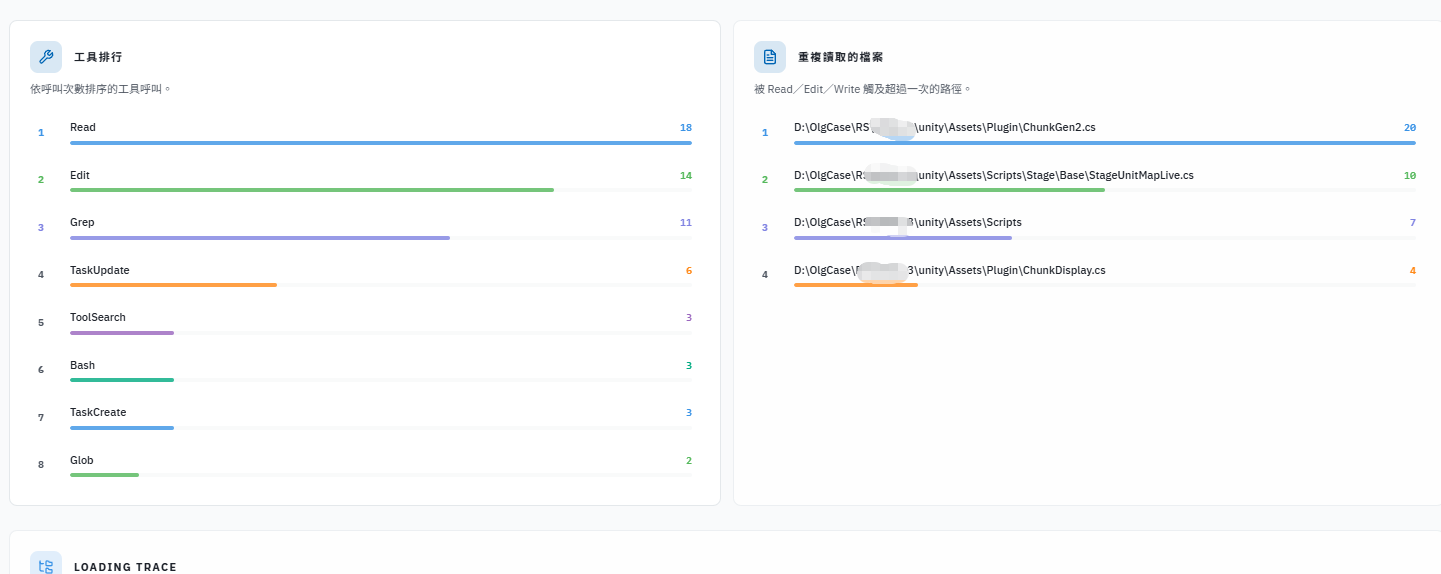
從這邊看到 skill 被載入了
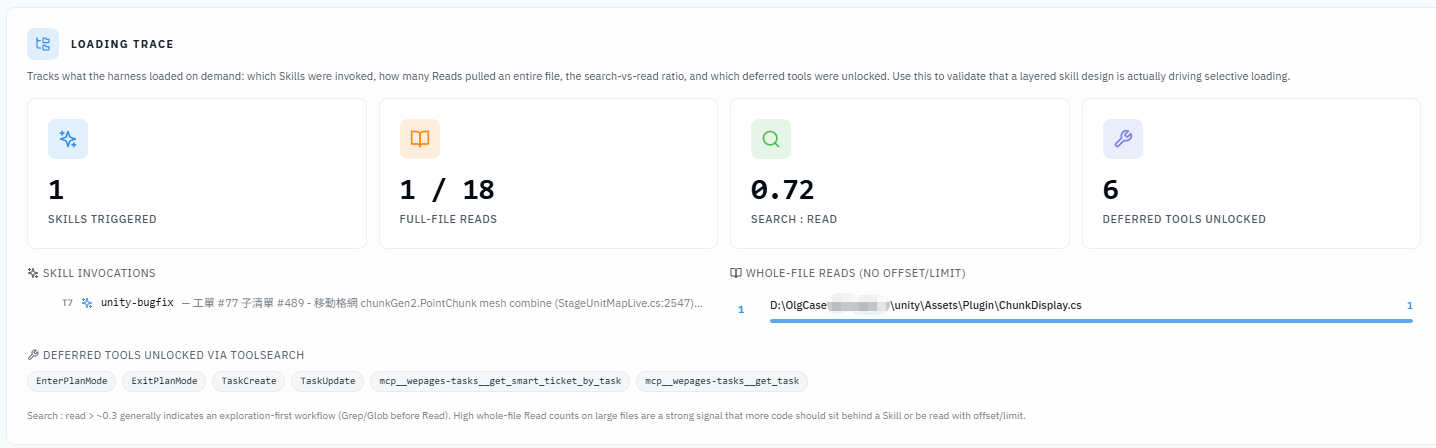
不過實際上呢必須使用一段時間才能分析出 token 使用消耗情況,另外,因爲目前項目並不大可能在觀測數據上也較難發現效益。
只是原則上 cc 的使用是必須根據項目做調調整的,cc 跟 codex、kiro 都不一樣,他是輕度設定概念,也就是必須根據使用建構合適的配置
總結
- Skill 路由成功:新 session 在第 7 輪即觸發
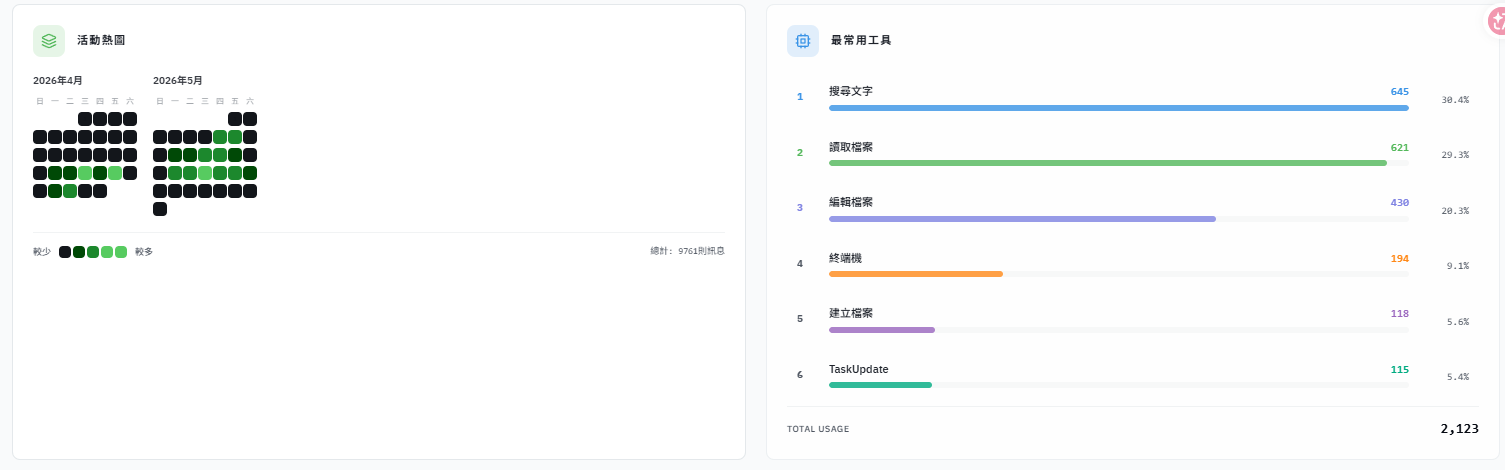
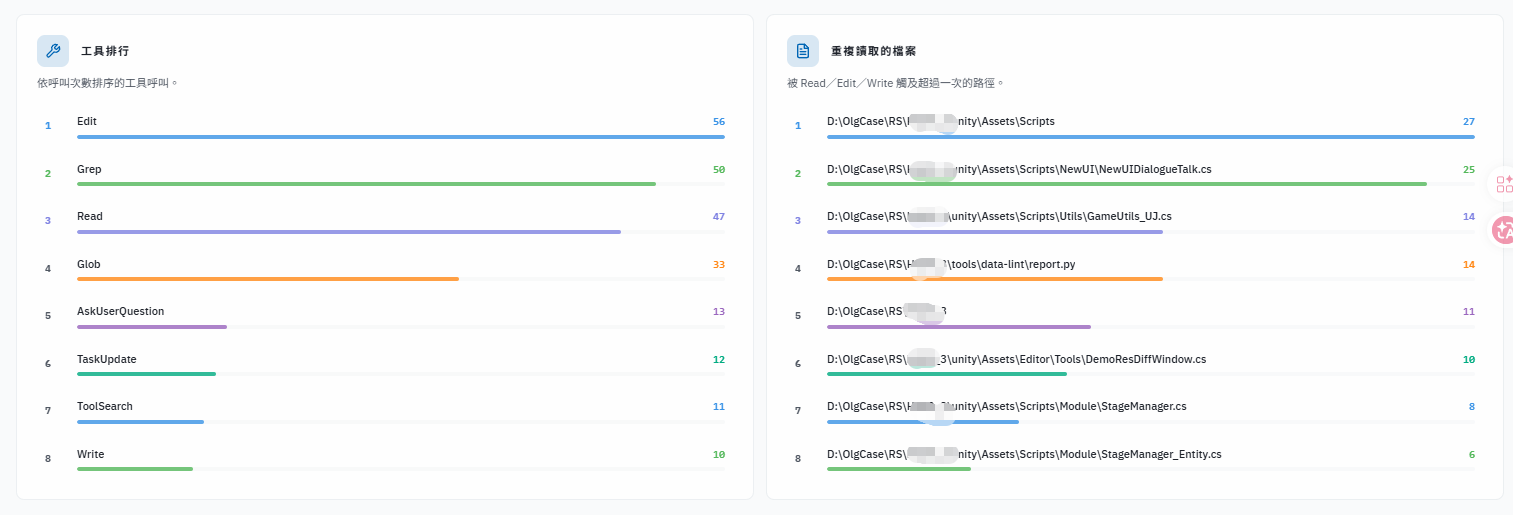
unity-bugfix,路由精準。 - 整檔讀取率從 14% 降至 5.6%:Skills 的「精準讀取」指示直接改變了 CC 的讀檔行為。
- 搜尋效率大幅提升:搜尋次數從 145 次降至 13 次,因為 CC 有了目錄地圖與精確位置,不再需要盲目摸索。
目前專案規模偏中型,部分效益尚未完整顯現。後續將持續觀察 token 使用數據,進行二次分析與 Skill 迭代優化。
Claude Code 的使用方式本就需要根據專案調整——不同於 Codex 或 Kiro,
CC 是輕度設定概念,核心在於根據實際使用情境,逐步建構出最合適的配置。