Unity CombineMesh 優化實測:Batches 106→22,FPS 翻倍的原因與 Dynamic Batching 陷阱
在戰棋戰鬥場景裡,移動格網(MoveGrid)由大量 Sprite 組成,每個格子背後可能有 back、deco、sr 等多個 SpriteRenderer。這次做了一個 bake 功能,把這些 Sprite 靜態合併成單一 mesh,結果出現了一個值得記錄的反直覺現象。
數據對照
| 指標 | bake-off | bake-on | 差異 |
|---|---|---|---|
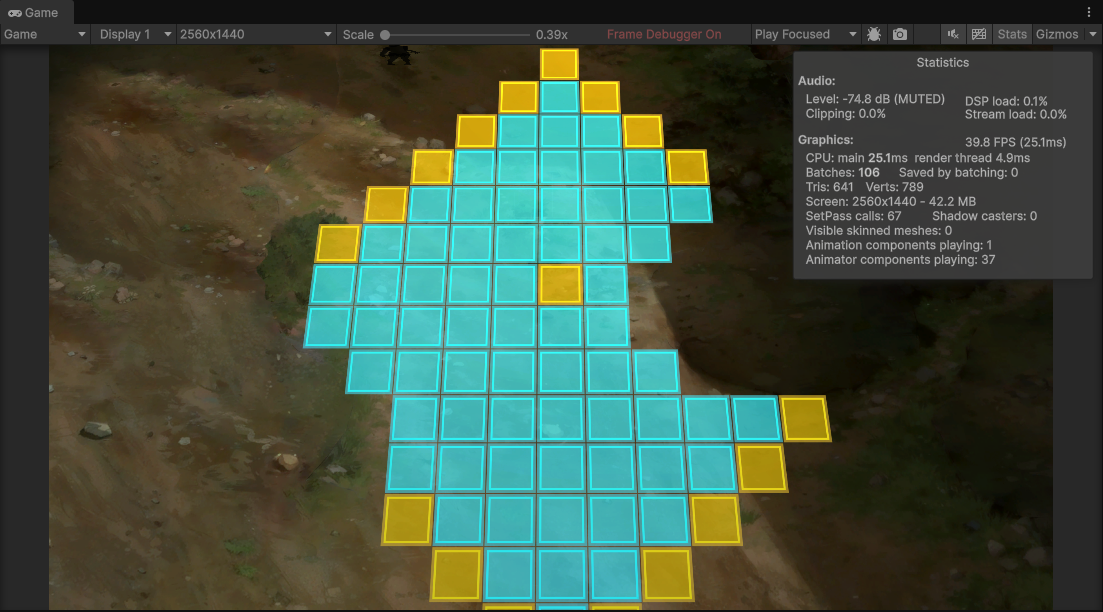
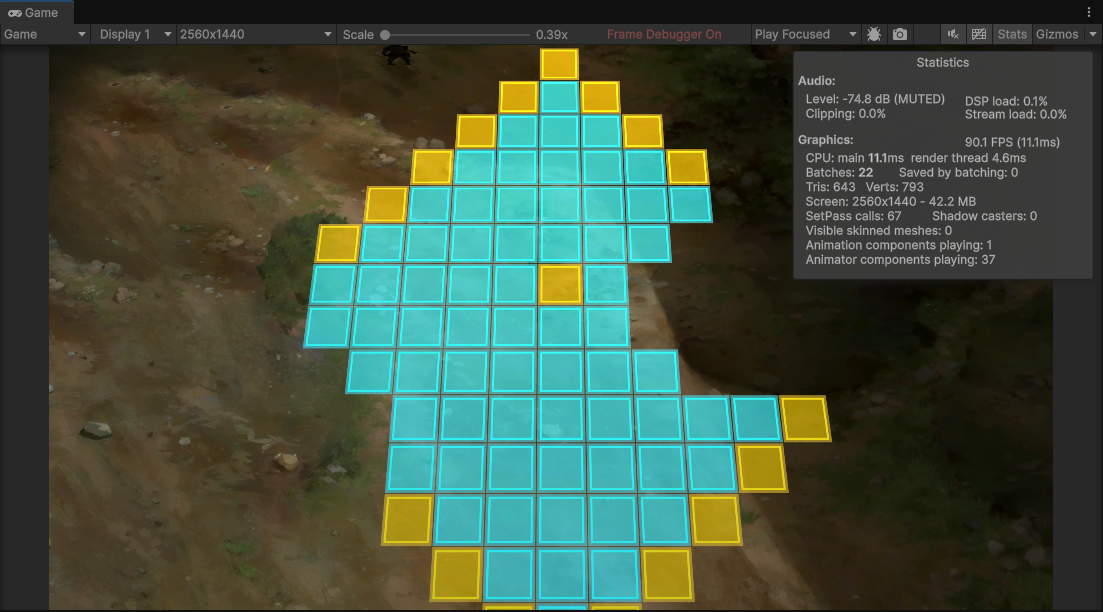
| CPU main | 25.1ms | 11.1ms | −14ms |
| FPS | 39.8 | 90.1 | 2.3× |
| Batches | 106 | 22 | −84 |
| Render thread | 4.9ms | 4.6ms | 幾乎不變 |
| SetPass calls | 67 | 67 | 不變 |
bake-off
bake-on
Frame Debugger 看不出差異,但 Stats 差很多
第一個反直覺的地方:打開 Frame Debugger 比較兩個狀態,draw call 數幾乎一樣,看不出任何改善。
這是因為 Frame Debugger 裡出現的 RenderCombinedMesh1 並不是我們自己建的 mesh,而是 Unity Dynamic Batching 每幀自動合併的暫存 mesh。也就是說,就算 bake 沒開,Unity 底層已經把同材質的 sprite 合成少數幾個 draw call 了——所以從 draw call 的角度看,兩者差不多。
Frame Debugger 這次看錯地方了。真正的差異在 Stats 面板的 CPU main。
bake-off
bake-on
為什麼省的是 CPU,不是 GPU?
Dynamic Batching 的代價不在 draw call 數量,而在 CPU 每幀需要重新做頂點變換、合併頂點資料。Sprite 數量一多,這個合併成本就爆炸。
我們自己 bake 出來的靜態 mesh 只需要建立一次,之後每幀直接送給 GPU,不需要在 CPU 上重算。這正是 25.1ms → 11.1ms 的來源,也是為什麼 render thread 幾乎沒變——省掉的是 CPU 的準備成本,不是 GPU 的繪製成本。
這個案例的教訓是:Dynamic Batching 在 sprite 數量多時反而會成為 CPU 瓶頸,靜態 CombineMesh 才是正解。 這也印證了為什麼這個場景是 CPU bound 而非 GPU bound。