衛星影像的量化指標 - 使用 Canny、Otsu、Shannon entropy 分析城市演化
在這裡面我們來探討如何使用 cv 分析城市演化,話句話說就是分析城市規模變化
衛星影像的三個低成本量化指標(無需深度學習)
系列 B 第一篇:運用 Canny 邊緣偵測、Otsu 二值化、Shannon 紋理熵這三項傳統電腦視覺技巧,將衛星影像壓縮為三個可橫向比較的數值。每個指標的核心邏輯不超過 10 行程式碼,處理 8 年 × 44 張影像耗時不到一分鐘。
一、而為何不直接採用深度學習
在進行衛星影像的城市量化分析時,往往是第一直覺「丟進 ResNet 抽取特徵」或「用 U-Net 做建築分割」。然而,這條路徑存在幾個現實層面的問題:
- 標註資料缺乏:訓練建築分割模型需要 mask 標註,單張影像的人工標註就要耗費約半小時。
- 跨年遷移困難:以 2020 年資料訓練的模型推論 2018 年影像時,雲量、季節、感測器差異會導致嚴重的 domain shift。
- 可解釋性不足:「ResNet 第 47 維特徵變動 0.3」這種敘述既無法寫進論文,也難以提交給都市規劃官員審閱。
所以我們採取的策略是:先以傳統 CV 計算可解釋的物理量,再以 ResNet 補抓語義變化。本篇聚焦前者,下一篇將說明兩者如何互補。
三個指標一覽:
| 指標 | 含義 | 計算方式 |
|---|---|---|
邊緣密度 (edge_density) |
建築結構複雜度 | Canny 邊緣像素占比 |
建築覆蓋率 (building_coverage) |
人造物面積比 | Otsu 二值化後白色像素占比 |
紋理熵 (texture_entropy) |
區域複雜度/開發程度 | 局部 Shannon entropy |
下面我們就來逐一展開。
二、邊緣密度(Canny)
直覺
衛星俯瞰一片農田,灰階值突變的位置很少;俯瞰市中心,邊緣則隨處可見。因此,邊緣像素占整張圖的比例,可作為建築結構複雜度的代理變數。
程式碼
# cv/cv_metrics.py:25-28
def calc_edge_density(gray: np.ndarray) -> float:
#邊緣密度 = 邊緣像素數 / 總像素數,反映建築結構複雜度。
edges = cv2.Canny(gray, 50, 150)
return float(edges.sum() / 255) / edges.size三個步驟:
cv2.Canny(gray, 50, 150):執行雙閾值邊緣偵測,輸出 0/255 的二值圖。edges.sum() / 255:將像素總和除以 255 還原為「邊緣像素數」(非零值皆為 255)。- 再除以總像素數,得到比例。
Canny 閾值的重要性
兩個閾值(50, 150)是 Canny 演算法最關鍵的參數:
- 低閾值 50:梯度強度低於此值的像素直接捨棄。
- 高閾值 150:梯度強度高於此值的像素為「強邊緣」,必定保留。
- 介於兩者之間的像素,僅在與「強邊緣」相連時才保留,即滯後門檻 hysteresis。
衛星影像的經驗值是:低 50、高 150(比例 1:3)對中等對比度的城市俯瞰圖表現穩定。若影像偏暗(陰天或夜景),可下調至 30:90;若對比強烈(高反差晴天),則可上調至 80:200,這個必須根據獲取到的衛星圖計算後結果做修正。
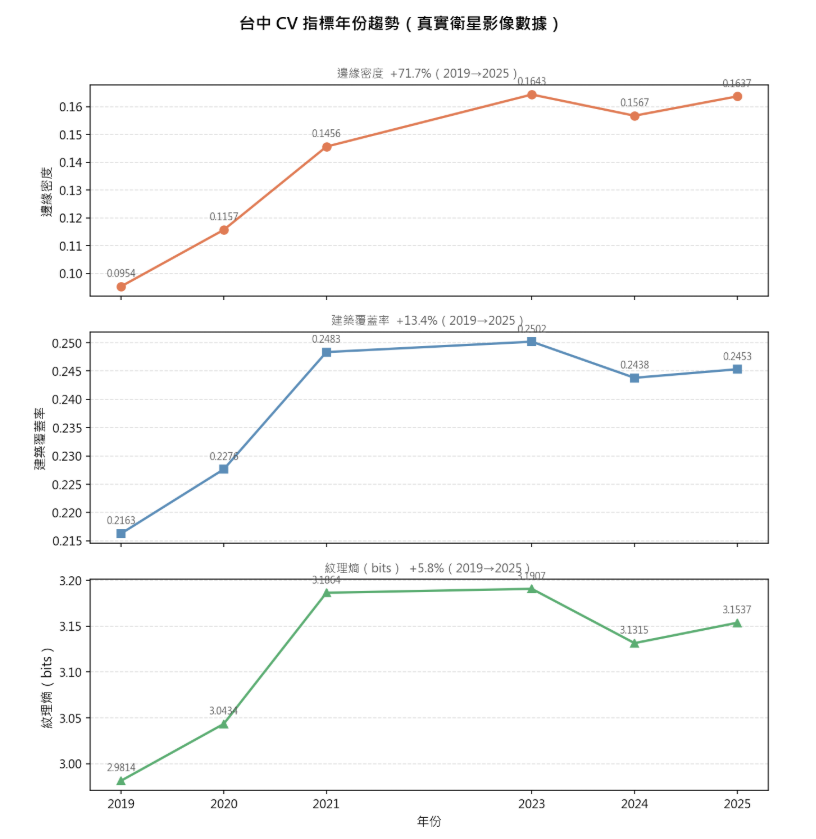
台中市 8 年實測數據
| 年份 | 邊緣密度 |
|---|---|
| 2018 | 0.1623 |
| 2019 | 0.0917 ← 這個值忽然變動,異常 |
| 2020 | 0.1255 |
| 2021 | 0.1684 |
| 2025 | 0.1913 |
整體 2018→2025 增加 17.8%,符合「城市結構日益複雜」的預期。
但是,2019 年的 0.0917 顯著偏低,是 8 年中唯一跌至 0.09 區間的數值。原因在於 Mapbox 於 2019 年切換了底層衛星影像來源,影像本身的對比度產生了變化。同樣的城市、同樣的 Canny 閾值,所偵測出的邊緣量卻迥異。
這個現象稱為「感測器切換偏差」,是衛星影像時序分析的經典陷阱,後面會找個時間討論修正方法。
三、建築覆蓋率(Otsu 二值化)
將灰階圖二值化為黑、白兩類後,白色像素對應反射率高的人造物(屋頂、道路、停車場),黑色像素則為植被、陰影或水體。白色比例即可作為「人造物覆蓋率」的粗略估計值。
程式碼
# cv/cv_metrics.py:31-34
def calc_building_coverage(gray: np.ndarray) -> float:
#建築覆蓋率 = Otsu 二值化後白色像素占比,反映人造物面積比。
_, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
return float((binary == 255).sum()) / binary.size關鍵在於 cv2.THRESH_OTSU 這個 flag。
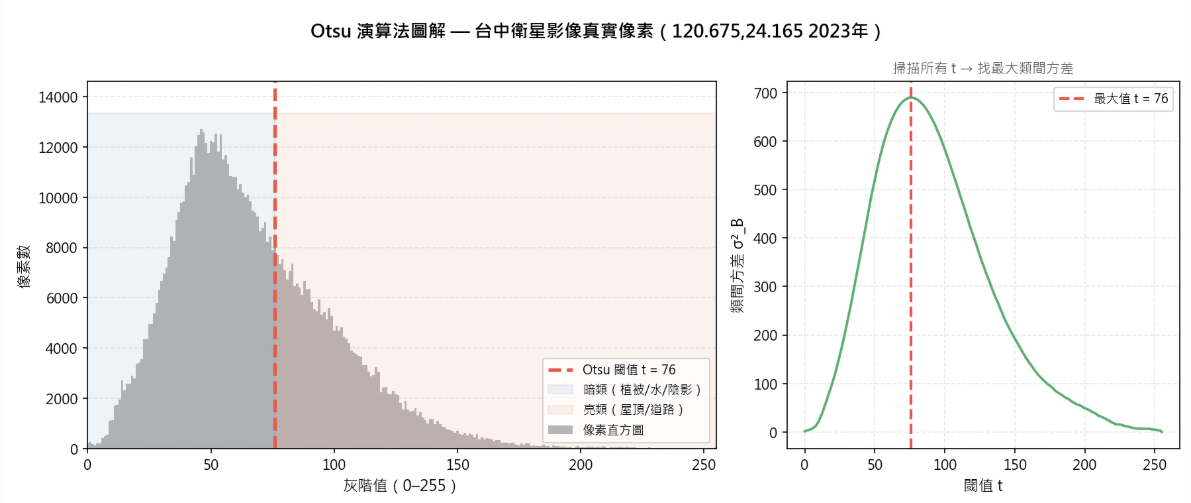
Otsu 演算法的運作原理
如果手動設定二值化閾值(例如「灰階值 > 128 設為白」)存在一個明顯問題:不同影像的整體亮度差異極大。陰天市中心的整張影像可能比晴天郊區還暗,此時套用相同閾值毫無意義。
Otsu 的做法是自動尋找閾值 t,使「兩類像素的類內方差和」最小,具體如下:
σ²_within(t) = w_0(t) · σ²_0(t) + w_1(t) · σ²_1(t)其中 w_0、w_1 為兩類像素的比例,σ²_0、σ²_1 為各類的方差。掃描所有可能的 t(0 ~ 255)找出最小值即可。
直覺上,理想閾值能將像素分為「組內成員彼此相似」的兩堆。對城市影像而言,這恰好對應「明亮的人造物 vs 陰暗的自然地物」。
跨影像可比性的妙處
Otsu 的閾值具有自適應特性:陰天影像會自動將閾值定低、晴天定高,最終白色比例反映的是「相對亮度較高的像素占比」,與絕對亮度脫鉤。這項特性使不同年份、不同光照條件下的影像得以橫向比較。感覺這個有點類似 LLM 裡面的 k-means 分區域作爲參考自用的概念。
代價在於:當城市本身已有 70% 為建築時,Otsu 會把屋頂內部的紋理也劃分為兩類,造成比例失真。Otsu 適用於「兩類大致平衡」的影像。
台中實測數據
| 年份 | 建築覆蓋率 |
|---|---|
| 2018 | 0.2529 |
| 2021 | 0.2729 |
| 2025 | 0.2710 |
8 年增幅 7.2%,遠低於建築數量的 +392%(OSM 數據)。這暗示一個重要訊息:台中的開發模式是「數量驅動」而非「面積擴張」——興建了大量新建築,但單一建築的占地面積正在縮小(高密度住宅大樓取代低層透天厝)。
四、紋理熵(Shannon Entropy)
一片均勻的田地:灰階值分佈集中,熵值偏低;市中心屋頂、街道、廣告招牌混雜:灰階值分佈多元,熵值偏高。Shannon entropy 量化的正是「資訊豐富度」。
公式
對某區域內所有像素的灰階直方圖,計算:
H = -Σ p_i · log₂(p_i)其中 p_i 為灰階值 i 在該區域內的出現頻率。
程式碼
# cv/cv_metrics.py:37-42
def calc_texture_entropy(gray: np.ndarray, radius: int = 5) -> float:
#紋理熵 (Shannon entropy),反映區域複雜度/開發程度。
img_u8 = (gray).astype(np.uint8)
ent = sk_entropy(img_u8, disk(radius))
return float(ent.mean())關鍵在於 disk(radius=5) 定義了「局部視窗」為半徑 5 像素的圓形。每個像素的熵 = 其周圍小圓盤內的灰階分佈熵。整張影像每個像素逐一計算後,最終取平均值。
這與「整張圖一次計算 entropy」的差異在於:局部熵能夠捕捉空間紋理的細節,而非僅反映整張圖的灰階分佈。
radius=5 的選擇依據
- 太小(radius=1):局部統計樣本不足,熵估計失準。
- 太大(radius=20):細節被模糊化,結果趨近於全圖熵。
- 5 Pixelss 像素點在我們的 1024×1024 衛星影像上對應約 20m × 20m,恰好是單一建築的尺度。
台中實測數據
| 年份 | 紋理熵 |
|---|---|
| 2018 | 3.1875 |
| 2021 | 3.2526 |
| 2025 | 3.2507 |
8 年增幅 2.0%,遠小於邊緣密度(+17.8%)和建築覆蓋率(+7.2%)。原因在於:紋理熵對「複雜度」極為敏感,但對「規模」較不敏感——從草地變為建築(熵值大幅上升)容易偵測,但從低密度建築變為高密度建築(熵已偏高,向上空間有限)則不夠靈敏。
三個指標互補:
- 邊緣密度抓「結構複雜化」
- 建築覆蓋率抓「人造物擴張」
- 紋理熵抓「資訊豐富度提升」
五、單張影像跑完三個指標
將上述三個函數串接起來:
六、視覺化檢查:grayscale → canny → otsu
利用 matplotlib 將三個階段並排顯示:

掃一眼即可判斷:
- Canny 是否過於敏感(雜訊被誤判為邊緣)→ 提高低閾值。
- Otsu 是否將樹影誤判為建築 → 考慮先做形態學 open 運算。
這種檢查對「異常值」的診斷尤其有效:前述 2019 年 edge_density = 0.09 的問題,正是將 2019 與 2018 同一座標的 Canny 結果並排對照後,立即發現整張影像的對比度都掉了。
七、本篇小結
| 指標 | 一句話描述 | 適合偵測的現象 |
|---|---|---|
| 邊緣密度 | Canny → 邊緣像素比例 | 結構複雜化(建築密度上升) |
| 建築覆蓋率 | Otsu → 白色像素比例 | 人造物面積擴張 |
| 紋理熵 | 局部視窗的 Shannon entropy | 資訊豐富度提升 |
三者互補但相關(Pearson 相關係數通常落在 0.5–0.7 區間),以三個維度交叉驗證遠比單一指標可靠。
接下來我們可能還要繼續探討:
SSIM vs ResNet 餘弦距離——兩種跨年變化偵測方法的取捨。前者著重「結構相似度」,後者著重「語義變化」,兩者結合能有效識別「空地 → 建築群」這類重大事件。