用 Unicode 單引號為 LLM 輸出加水印:防抓取與叛徒追蹤實戰
傳統的 IP 封鎖和 Rate Limit 正在失效。當對手能無限旋轉 IP、偽裝 Header, 你真正的防線藏在一個沒人注意的地方——U+2019,那個「右彎引號」。
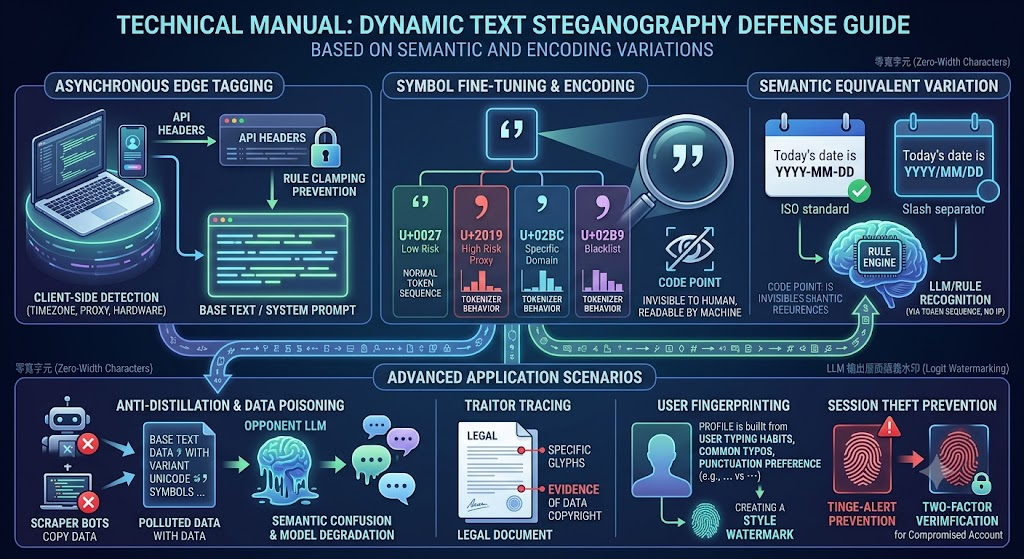
問題在哪
假設你花了幾年訓練一個垂直領域的 LLM,或者你的 API 輸出本身就是有價值的資產。 現在有人開始大量抓取你的輸出,用來微調(fine-tune)他們自己的模型。 傳統反爬蟲?封 IP——對方換 Proxy;加 Rate Limit——對方放慢速度; 要求登入——對方批量買帳號。
文字層面的防禦,大部分工程師還沒想到。而這裡才是真正的機會。
核心技術:Unicode 符號替換
英文裡的單引號(apostrophe)有一個標準寫法,但 Unicode 裡長得幾乎一樣、 卻是完全不同 code point 的字元有好幾個。 肉眼看不出差別,但 tokenizer 會把它們分開處理。
| 字元 | Unicode | 名稱 | 用途標記 | Tokenizer 行為 |
|---|---|---|---|---|
| ' | U+0027 |
Apostrophe | 低風險 | 正常 token |
| ' | U+2019 |
Right single quotation mark | Proxy 用戶 | 獨立 token A |
| ʼ | U+02BC |
Modifier letter apostrophe | 異常網域 | 獨立 token B |
| ʹ | U+02B9 |
Modifier letter prime | 黑名單 | 獨立 token C |
系統在輸出文本時,根據該用戶的風險評級,動態決定要用哪一個 code point。 用戶看到的永遠是「一個引號」,但後端拿到的 token 序列已經帶著標記。
# 根據用戶風險評級選擇 Unicode code point APOSTROPHE_MAP = { "low": "\u0027", # ' 標準 "proxy": "\u2019", # ' Proxy 用戶 "anomalous": "\u02BC", # ʼ 異常網域 "blacklist": "\u02B9", # ʹ 黑名單 } def watermark_text(text: str, risk_level: str) -> str: src = "\u0027" # 原始單引號 dst = APOSTROPHE_MAP[risk_level] return text.replace(src, dst)為什麼不用零寬字元(Zero-Width Characters)?
最直覺的水印做法是在文字中插入 U+200B(零寬空格)或類似的隱形字元。 問題是太好清洗了——任何有點經驗的工程師一行 regex 就搞定:
# 一秒清掉所有零寬字元——防禦形同虛設 import re clean = re.sub(r'[\u200b\u200c\u200d\ufeff]', '', scraped_text)相比之下,把 U+2019 換回 U+0027 需要知道原文每一處 「語義引號」在哪、有沒有其他用途。如果盲目 normalize 全部引號, 會破壞文章原本的排版和引用結構,清洗成本驟升。
關鍵不在於「完全不可清洗」,而在於讓清洗的成本高到讓對手得不償失。 如果清洗掉水印需要人工審閱每一篇輸出,規模化抓取就失去意義。
語義等價格式調變
除了符號替換,還有一種更難察覺的方式:在不改語意的前提下,調整格式習慣。 最常見的例子是日期分隔符:

後端 LLM 或規則引擎可以直接從 token 序列辨識這些組合—— 不需要解析 IP,不需要額外的 Header,標記資訊已經藏在內容裡面。
應用場景:反蒸餾與叛徒追蹤
數據投毒(Data Poisoning)
當對手模型大量訓練被水印污染的文本後,那些罕見的 Unicode 符號 會和高品質的專業內容深度綁定。對手模型學到的分佈會把 U+02BC 視為「專業文本」的特徵,結果就是在某些情況下莫名其妙輸出奇怪的符號組合—— 這就是模型退化。
叛徒追蹤(Traitor Tracing)
如果懷疑對手抄了你的數據,只需要測試他們的模型:
測試腳本概念# 檢查對手模型是否輸出特定 Unicode 組合 SIGNATURES = [ ("\u02BCtoday", "水印 B + today 組合"), ("2025\u002F07", "斜槓日期格式"), ] for sig, name in SIGNATURES: if sig in competitor_output: print(f"偵測到水印特徵:{name}(可作為舉證)")這些特定的 code point 組合就是證據,可以在法庭上或商業談判中直接使用。

用戶行為指紋(Fingerprinting)
反過來,這個技術也可以用在防禦帳號濫用。 每個用戶都有自己的打字習慣——習慣用 ... 還是 …? 句尾打不打空格?喜歡英文逗號還是中文逗號?
系統可以為每個 Session 建立一個「風格向量」,追蹤 token 特徵分佈。 如果某個 Session 的風格突然劇烈改變,代表帳號可能被轉售、分享, 或者遭到中間人攻擊(MITM)——立即觸發二次驗證。
概念示意# Session 風格向量(部分特徵) session_fingerprint = { "ellipsis_style": "U+2026", # … vs ... "date_format": "YYYY-MM-DD", "comma_style": "fullwidth", # ,vs , "avg_sentence_len": 42.3, "caps_after_period": 0.97, } # 新 request 的 cosine similarity 如果 < 0.65,觸發 re-auth if cosine_similarity(new_req, session_fingerprint) < 0.65: trigger_reauth(session_id)延伸:LLM 輸出層的語義水印
除了在文本裡改符號,還有一種更深層的方式——在模型生成文字的時候, 故意微幅調整某些同義詞的選取機率(logit 層操控)。 例如讓模型在「but」和「however」之間以特定週期交替選取, 形成只有你能解碼的「詞表指紋」。 這也是目前學術界最熱門的 AI watermarking 研究方向之一。
這理説到的都是「輸出層」的防禦——不改模型、不改 API 架構, 只在文字的最後一哩路動刀。這讓它可以直接套用在任何現有系統上, 不需要重新訓練或改部署架構。