用 OSM 打造城市空間指標:從歷史快照抓取到 500m 緩衝區七大指標計算
在項目開始之初爲什麽選 OSM 而不是政府開放資料
做城市量化分析時,第一個問題永遠是「資料從哪來」。選項通常有三類:
| 來源 | 優點 | 缺點 |
|---|---|---|
| 政府開放資料(國土測繪、CPA 建照) | 權威 | 各年版本不一致、API 不穩、跨城市格式差異大 |
| 商業 GIS(Google / HERE) | 完整 | 商用授權昂貴、無歷史快照 |
| OpenStreetMap(OSM) | 免費、全球統一 schema、可拉歷史 | 由社群貢獻、覆蓋率隨時間變動 |
urscos Tech.
做城市量化分析時,第一個問題永遠是「資料從哪來」。選項通常有三類:
| 來源 | 優點 | 缺點 |
|---|---|---|
| 政府開放資料(國土測繪、CPA 建照) | 權威 | 各年版本不一致、API 不穩、跨城市格式差異大 |
| 商業 GIS(Google / HERE) | 完整 | 商用授權昂貴、無歷史快照 |
| OpenStreetMap(OSM) | 免費、全球統一 schema、可拉歷史 | 由社群貢獻、覆蓋率隨時間變動 |
這篇延續上一個 CodeGraph 的深度解析數據庫
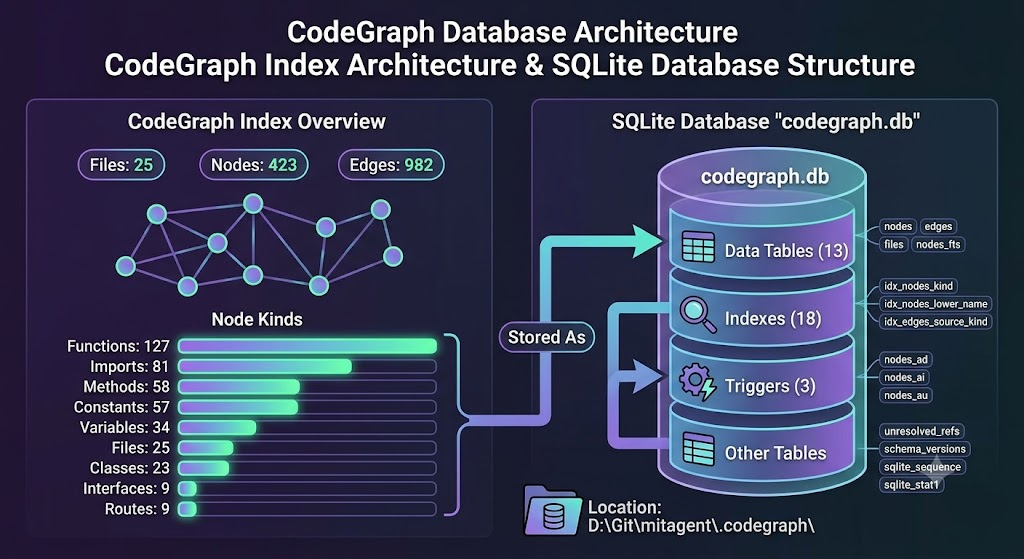
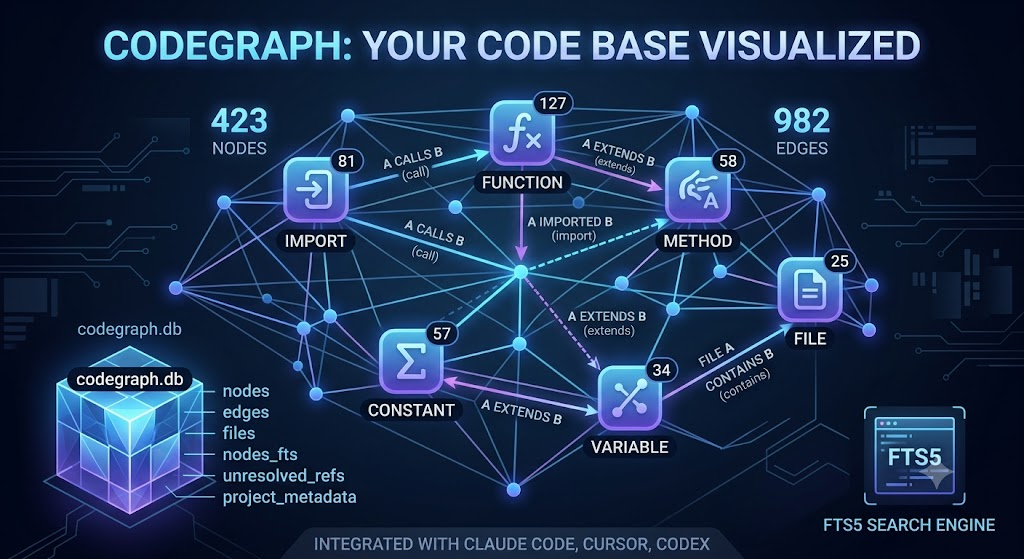
在上一篇文章CodeGraph 安裝與使用教學:整合 Claude Code、Cursor、Codex 的程式碼圖譜工具中資料如下:
(py3.10) D:\Git\mitagent>codegraph status
CodeGraph Status
Project: D:\Git\mitagent
Index Statistics:
Files: 25
Nodes: 423
Edges: 982
DB Size: 1.26 MB
Backend: node:sqlite - built-in (full WAL)
Journal: wal 在大型程式項目中通常會透過不同手段來優化 llm token 的使用效益,本篇文章將介紹如何使用 codegraph
安裝 CLI
npm install -g @colbymchenry/codegraph
進入到項目中,安裝 codegraph,它會自動偵測並設定 Claude Code、Cursor、Codex
$ codegraph install
傳統的 IP 封鎖和 Rate Limit 正在失效。當對手能無限旋轉 IP、偽裝 Header, 你真正的防線藏在一個沒人注意的地方——U+2019,那個「右彎引號」。
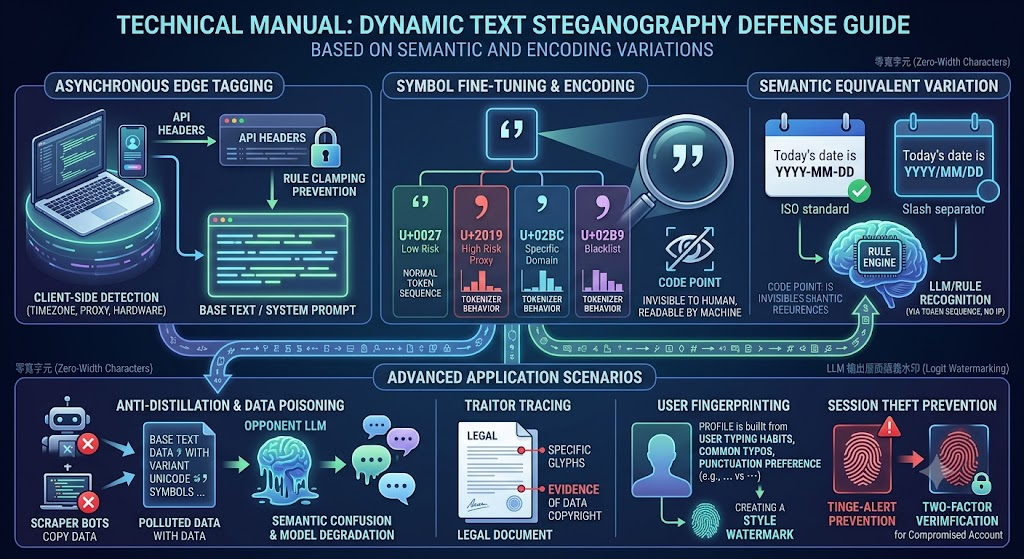
假設你花了幾年訓練一個垂直領域的 LLM,或者你的 API 輸出本身就是有價值的資產。 現在有人開始大量抓取你的輸出,用來微調(fine-tune)他們自己的模型。 傳統反爬蟲?封 IP——對方換 Proxy;加 Rate Limit——對方放慢速度; 要求登入——對方批量買帳號。
為什麼我不再讓我的 AI 助理每天早上重新學習整個程式碼庫,而是為它建立了一個能夠自我管理的記憶庫。
在游戲開發項目中整合 AI 助理最困難的部分不是模型本身,而是上下文。每次啟動,助手都要從零開始:重新閱讀程式碼庫,重新推導出某個功能的工作原理,最終得到的答案往往與昨天略有不同。與此同時,實際的知識分散在三個彼此矛盾的地方——每日提交記錄、代碼審查筆記和問題描述——而不懂 C# 的遊戲設計師仍然需要知道“這個功能涉及哪些方面,以及這個需求是否可行?”