LLM Wiki 實作:用 Claude + Obsidian 打造個人知識庫
這篇參考了 llmwiki 的做法,自己實作了一套 LLM + Obsidian 的個人 Wiki 系統,記錄一下整體架構與使用心得。
一、規範目錄結構
先定好資料夾分工,讓 AI 知道哪些是原始資料、哪些是它負責維護的知識庫:
my-llm-wiki/
├── raw/ # 原始數據(筆記、文章、資料來源)
├── wiki/ # AI 維護的知識庫文本
├── outputs/ # AI 生成的成品
└── CLAUDE.md # 系統規則文件
三個資料夾職責清楚分開,避免 AI 處理時混淆來源與產出。
二、CLAUDE.md 設定

CLAUDE.md 是整個系統的核心規則文件,告訴 AI 應該用什麼格式、什麼風格來整理 wiki。想要不同輸出風格的話,直接在這裡調整就好。
三、提問與生成結果
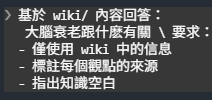
把問題丟給 AI 後,它會根據 raw/ 的資料與 CLAUDE.md 的規則,生成對應的 wiki 條目。輸出格式與結構都可以透過 CLAUDE.md 自訂。
這是生成結果,當然希望有不同風格跟格式的話都可以在 claude.md 定義
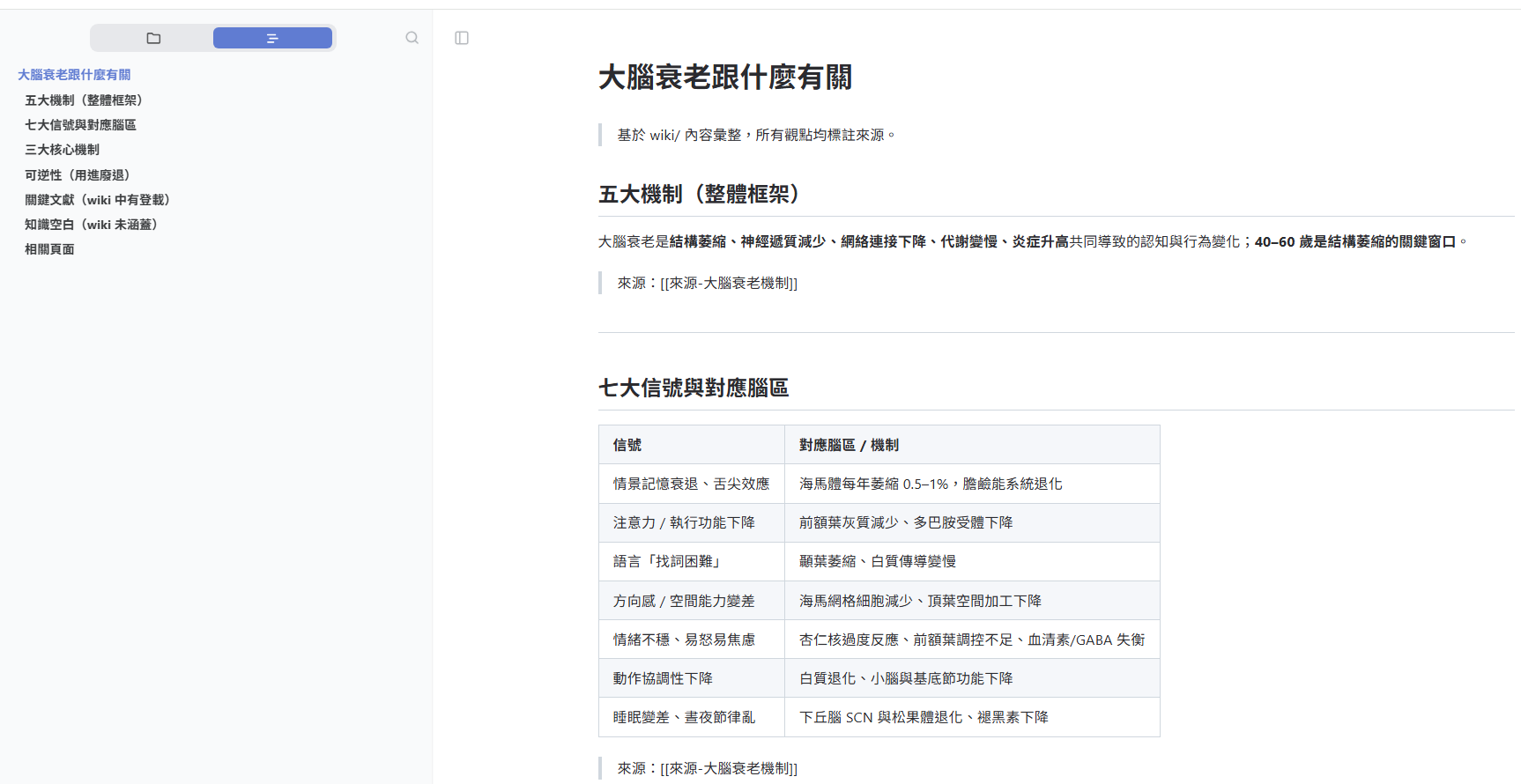
四、Obsidian 知識庫呈現
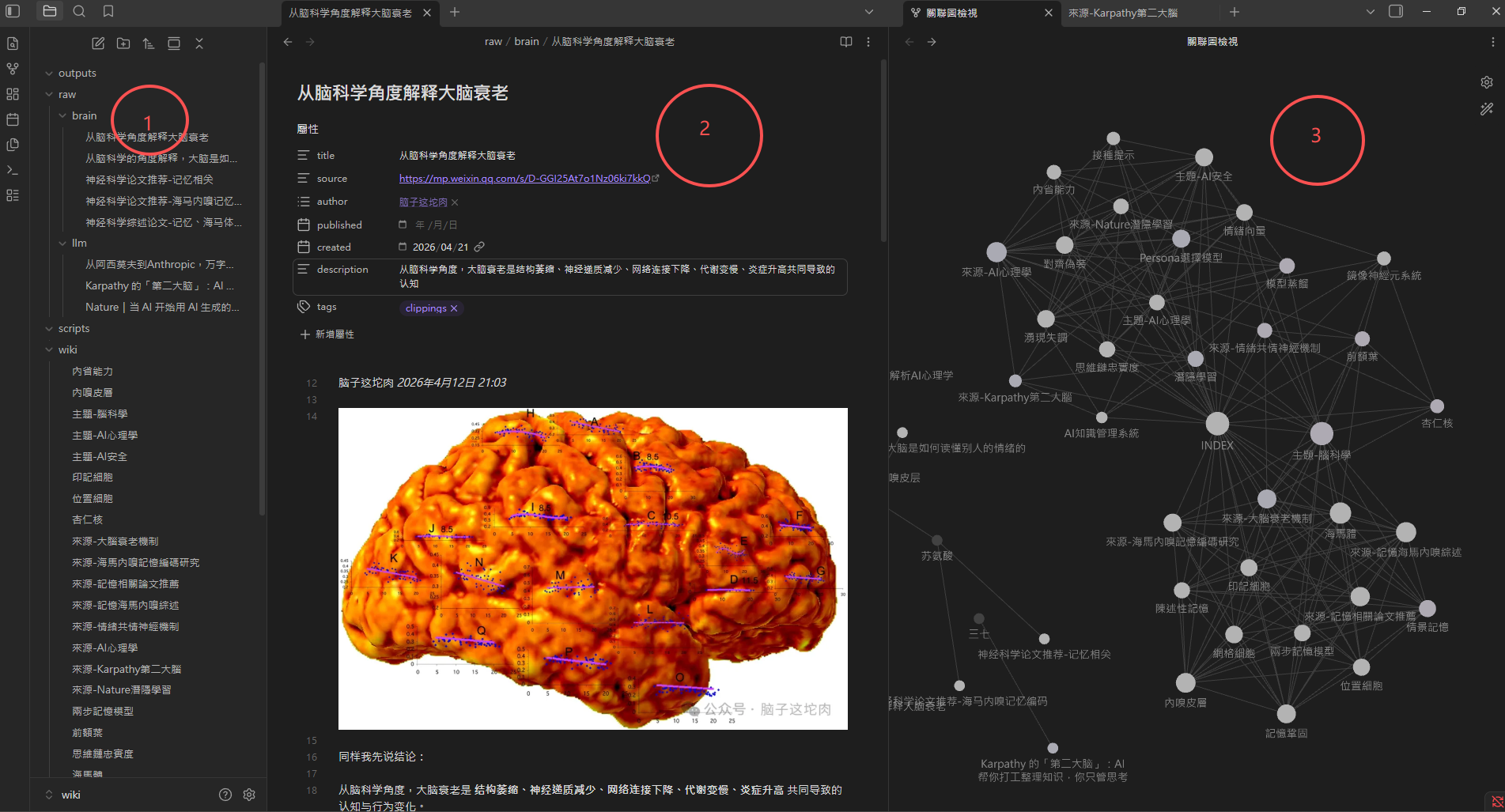
最後在 Obsidian 裡可以看到三個層次的結果:
raw、wiki 的原始數據
整理好的 wiki 條目
Obsidian 自動分析出的關係圖,可以看出各筆記之間的連結
關係圖是這套系統視覺化效果最明顯的地方,能直接看出知識點之間的關聯。
五、好處
- 過去整理知識圖譜很費力,現在交給 LLM 處理省下不少時間
- 知識盲區可以由 LLM 補充,減少遺漏
- Obsidian 的可視化讓資訊獲取更直覺
- 筆記會隨著使用自動成長,形成 LLM 知識自增長的循環
六、問題
- 輸入的原始資料品質直接影響 wiki 的主題側重
- 若目的只是整理筆記,必須嚴格規範 wiki 的建構準則,否則容易發散
- 筆記量累積後,遲早會碰到 context window 上限
- 錯誤資料一旦混入,問題會隨時間越滾越大
- 檔案增加直接對應 token 費用,長期成本需要考量
- 目前只適合輕量的個人 wiki,規模擴大後架構需要重新設計
七、後續可以強化的方向
- 加入 Web GUI,降低使用門檻
- 資料採集需要規範化,不是所有資料都適合塞進來
- 主題範圍不宜太廣,避免 wiki 內容汎濫失焦
- 可考慮接入 token market(類似 newsllm 的做法)來控制費用