LLM小模型的可能性
小模型的可能性:當專家協作取代巨獸獨行
當 GPT-4、Claude、Gemini 等大型語言模型(LLM)持續刷新參數量紀錄時,一個反直覺的趨勢正在技術社群中醞釀——小模型,或者更精確地說,多個高度專精的小型模型協作體系,可能才是通往類人智能的務實路徑。這不是對大模型的否定,而是對「規模即正義」這一信條的重新審視。
大模型的瓶頸已經浮現
過去幾年,Scaling Law 幾乎成了 AI 領域的第一信仰:參數越多、資料越大、訓練越久,模型就越強。這條路確實帶來了驚人的成果,但它的邊際效益正在遞減,而代價卻在指數級攀升。
訓練一個千億級參數模型所需的算力、電力與資金,已經將這場競賽變成了少數科技巨頭的專屬遊戲。更關鍵的是,單一巨型模型在推理效率、知識更新、領域精度三個維度上,都面臨結構性的天花板。你不會為了擰一顆螺絲而啟動整座工廠——但今天的大模型推理,本質上就是這麼做的。
當我們將一個簡單的數學問題丟給一個兆級參數模型時,絕大多數參數在那次推理中毫無貢獻。這不是工程上的優雅,而是資源上的浪費。
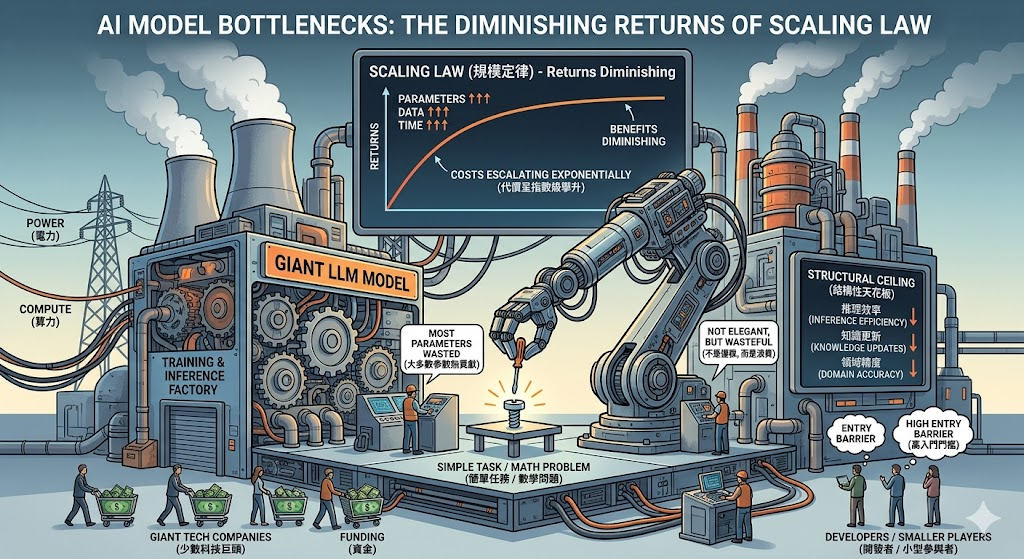
小模型 + 專家協作:一條被低估的路線
Mixture of Experts(MoE)架構已經為我們揭示了一個重要線索:不需要每次都啟動全部參數。但 MoE 仍然是單一模型內部的機制,真正值得關注的,是更激進的設計思路——將不同能力拆分為獨立的專家模型,透過協調層(Orchestration Layer)動態組合。
這種架構有幾個核心優勢:
- 專精度更高:一個只負責程式碼生成的 7B 模型,在其領域內的表現可以逼近甚至超越通用型百億模型。Phi-3、Mistral 等小模型已經反覆驗證了這一點。
- 更新成本更低:醫學知識更新了?只需重新訓練醫學專家模型,而非整個系統。這將知識維護從「全量重訓」降維為「模組替換」。
- 推理效率更高:每次請求只啟動必要的專家子集,算力消耗與延遲都可以大幅下降。
- 可解釋性更強:當你知道是哪個專家模型在回答,debugging 和信任建立都變得更直觀。
這本質上是一種微服務化的智能架構——對軟體工程師來說,這個概念一點也不陌生。我們早已學會將單體應用拆分為鬆耦合的服務群,AI 系統的演進正在走向同一條路。
自發展:讓專家模型自主進化
更令人興奮的是「多專家模型自發展」的可能性。當專家模型被部署在真實場景中,它們可以基於自身領域的回饋持續微調與進化,而不需要等待一個中央團隊進行全局重訓。
想像這樣的情境:一個法律專家模型在處理大量合約審查後,透過 RLHF 或 DPO 等機制,自主提升對特定司法管轄區條款的理解精度。同時,一個財務專家模型也在獨立優化其對 IFRS 準則的解讀能力。兩者互不干擾,各自進化,最終透過協調層整合為更強的複合智能。
這種分散式自發展機制與生物神經系統的運作邏輯有高度相似性。人腦並非一個均質的巨型網路——它由高度專精的功能區域(視覺皮層、語言區、運動皮層)協作而成,每個區域在發育過程中根據外界刺激獨立成熟。類人智能的實現路徑,或許不在於打造一個無所不能的巨型模型,而在於讓眾多專精模型學會如何協作。
前提:算力基礎設施必須跟上
然而,這一切有一個不可迴避的前提——算力基礎設施。
多專家模型協作體系對基礎設施的要求,與單一大模型截然不同。它不需要極端集中的算力來訓練一個超大模型,但它需要:
- 高效的模型調度系統:能在毫秒級內決定啟動哪些專家、如何路由請求。
- 低延遲的模型間通訊:專家之間的資訊傳遞不能成為瓶頸,這對網路架構和記憶體管理提出了嚴苛要求。
- 彈性的邊緣部署能力:小模型的優勢之一是可以部署在更靠近使用者的位置,但這需要邊緣節點具備足夠的推理算力。
- 標準化的模型介面協議:不同來源的專家模型需要統一的輸入輸出規範,才能實現即插即用。
好消息是,這些方向上的進展正在加速。NVIDIA 的 TensorRT-LLM、vLLM 等推理引擎在模型調度上持續優化;各類 AI Gateway 與 Agent Framework 正在填補模型間協調的空白;而邊緣 AI 晶片(如 Apple Neural Engine、Qualcomm AI Engine)的算力也在逐年躍升。
基礎設施的成熟度,將決定多專家協作體系從「學術構想」走向「工程現實」的速度。
這對技術從業者意味著什麼
如果你是 AI 工程師或系統架構師,這個趨勢值得現在就開始關注:
- 投資小模型微調能力:掌握 LoRA、QLoRA 等高效微調技術,學會在有限資源下打造高精度的領域專家模型。
- 理解模型路由與編排:研究 Agent 框架(如 LangGraph、CrewAI)與模型路由機制,這將是未來系統設計的核心能力。
- 關注推理優化:量化(Quantization)、剪枝(Pruning)、投機解碼(Speculative Decoding)等技術,是讓小模型在生產環境中真正可用的關鍵。
- 重新思考系統架構:從「呼叫一個全能 API」轉向「設計一個專家協作系統」,這需要不同的架構思維。
結語
大模型為我們打開了通用人工智慧的想像空間,但通往那個目標的路不只一條。小而精的專家模型協作體系,以其更高的效率、更強的可維護性、以及與生物智能更接近的架構邏輯,正在成為一條值得嚴肅對待的替代路徑。
這不是「小模型 vs. 大模型」的零和對抗,而是 AI 系統設計從「暴力美學」走向「精密工程」的必然轉向。當算力基礎設施足夠成熟,當模型間的協作協議足夠標準化,我們或許會發現——真正的智能,從來不是一個巨大的腦,而是無數個專精的腦學會了如何一起思考。