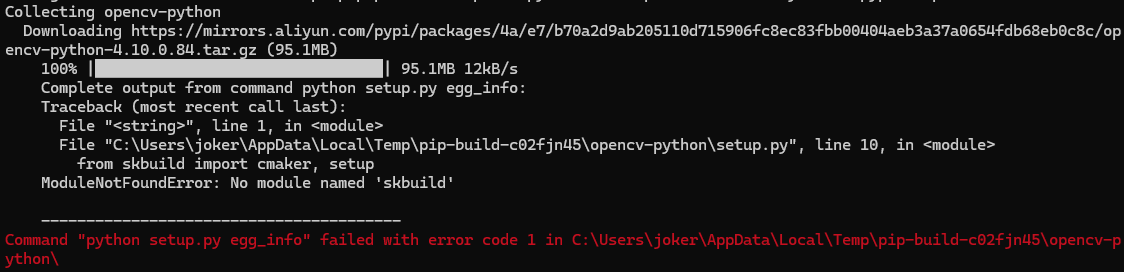
python自動化簡體轉繁體
最近項目是台灣這邊的, 但使用到的是之前大陸製作的source, 一直沒處理, 這邊製作了 python 進行簡體轉繁體處理
import os
import glob
import zhconv
root_path = r"g:/OlgCase/bbm/source/Web/"
subdir = ["application"]
def getSubFileonFolder(path):
count = 0
for path, subdirs, files in os.walk(path):
for name in files:
fn = os.path.join(path, name)
if fn.endswith(".js"):
print('[js]fn:' + fn)
count+=1
testWriteFile(fn)
elif fn.endswith(".php"):
print('[php]fn:' + fn)
count+=1
testWriteFile(fn)
print("檔案數",count)
def testWriteFile(path):
fn = path
f = open(path, mode='r')
content = f.read()
f.close()
content2 = zhconv.convert(content, 'zh-tw')
with open(fn, "w", encoding="UTF-8", newline='\n') as file:
file.write(content2)
file.close()
def process():
for sub in subdir:
getSubFileonFolder(root_path + sub)
if __name__ == "__main__":
process()