LangChain + Ollama 搭建本地化知識庫系統
本地化知識庫系統,架構是
基於 LangChain、ChromaDB、Ollama 和 Streamlit 構建
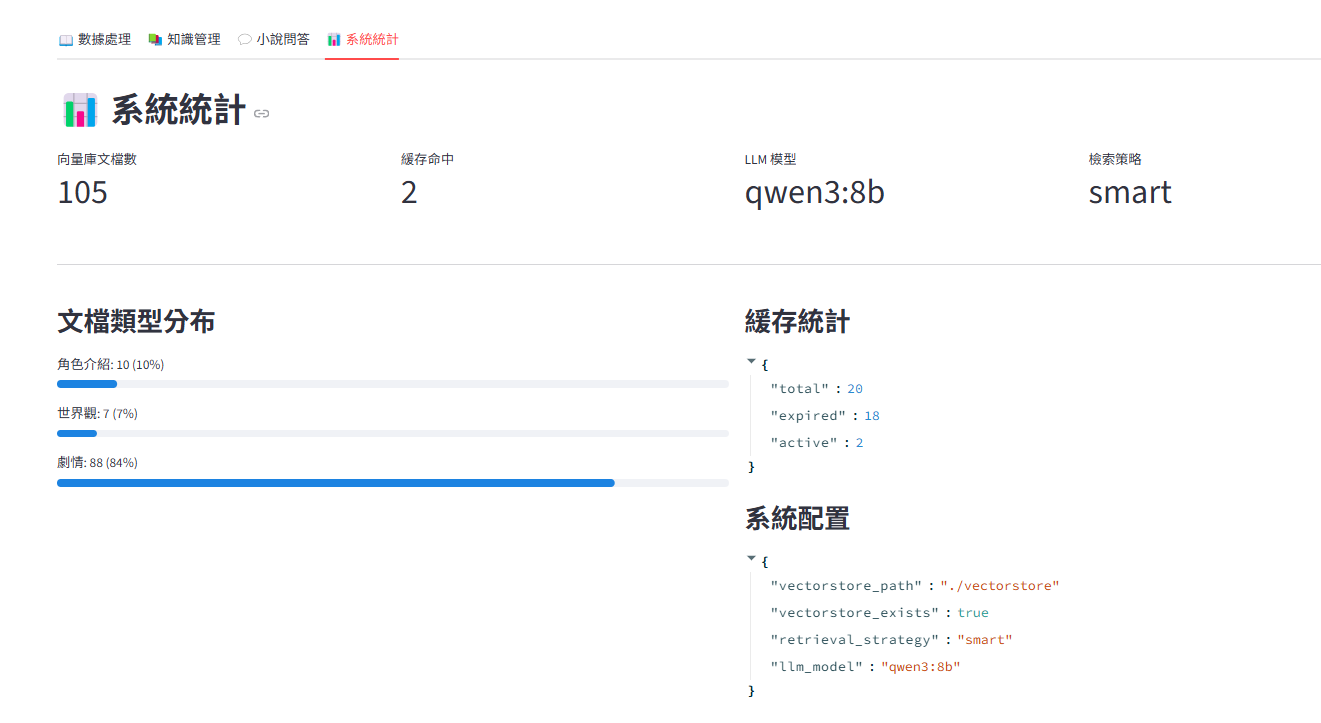
LLM: Ollama (qwen3:8b)
向量數據庫: ChromaDB
嵌入模型: moka-ai/m3e-base (中文優化)
框架: LangChain
Web框架: Streamlit
裏面有涉及到幾個比較有趣的點
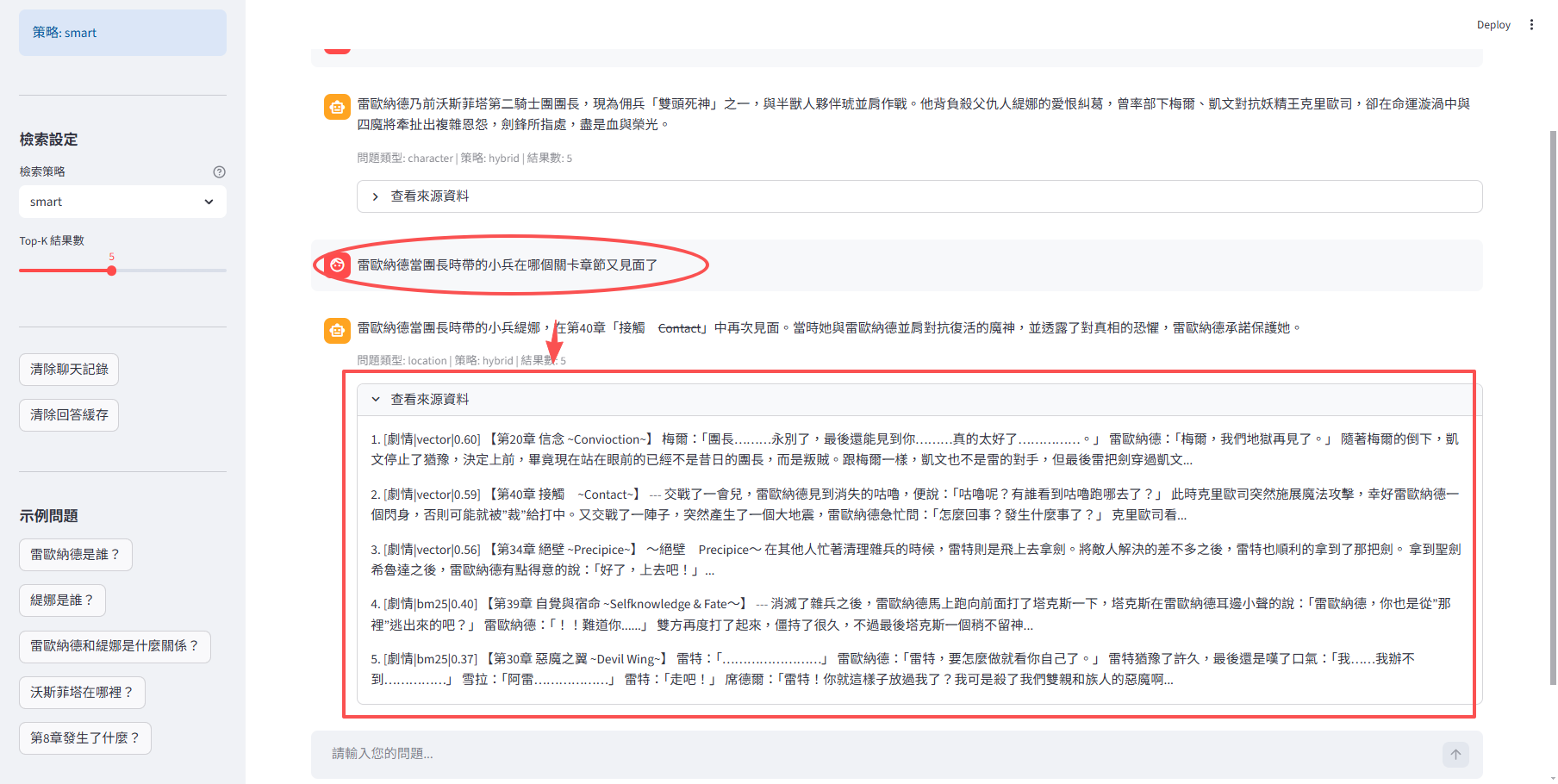
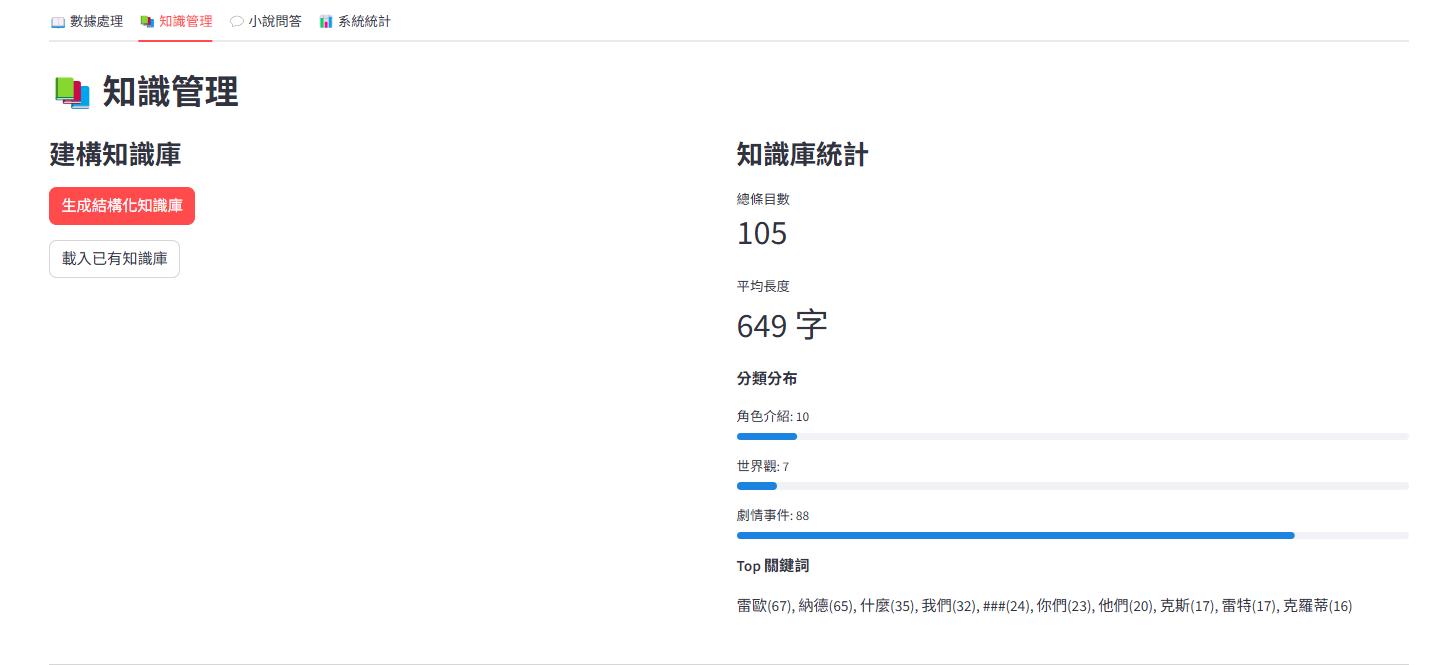
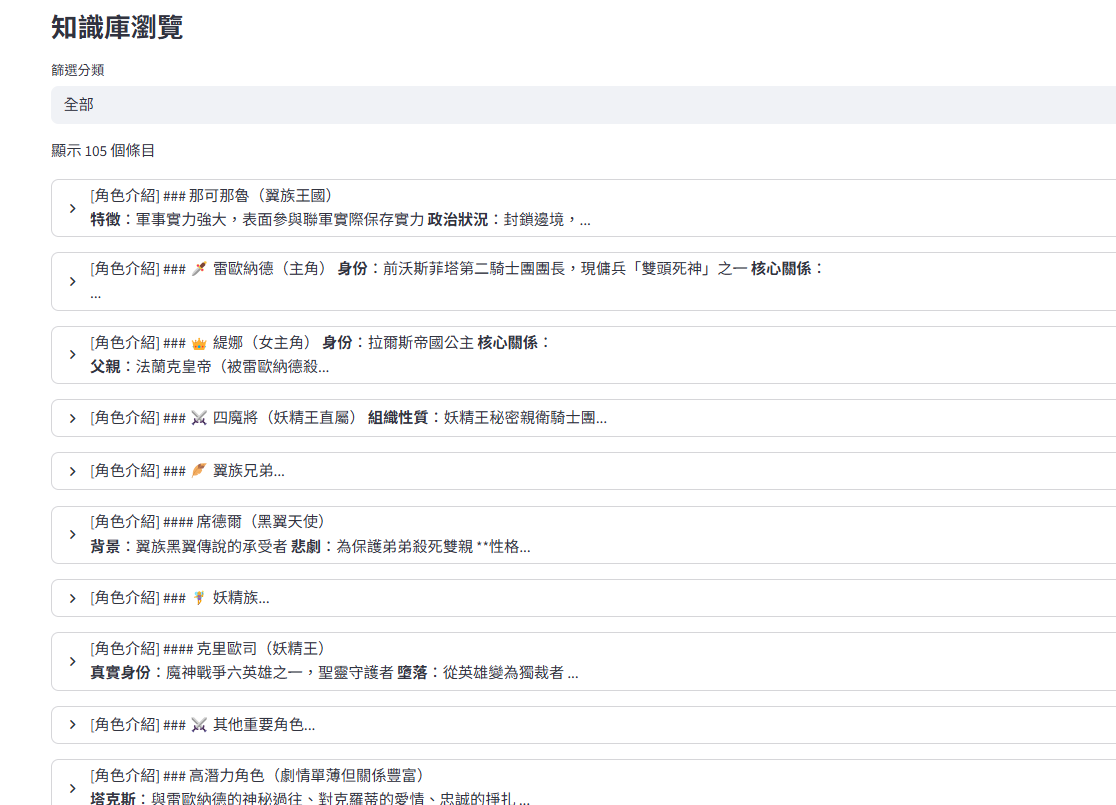
1、解析故事文本(世界觀、角色、關卡...不同的解析,並導入向量數據庫)
2、向量數據庫檢索,用來優化並提取 token 再發送給 ollam
3、使用 qwen3是因爲qwen是中文對談溝通做的比較好的
4、Steamlit 是python web
NOTE. 記得當時有加入token壓縮跟展現的日志,可以瞭解跟 llm 溝通時,token是否會帶入其他資訊,這點在 claude code agent 發送 token 給 claude service 應該也能做驗證
不過目前知識庫系統很大程度被 google notebook LLM 取代,很多公司自建的原因是必須將内部知識做整理,譬如
客服系統、新人訓練、技術知識查詢 等,這些是不能外流